

早在2019年4月,台积电宣布其5nm工艺已经开始风险生产。到IEDM 2019,他们对经过1000小时HTOL并将于2020年1H投入量产的工艺进行了详细描述。据介绍,这5nm的技术是在7nm基础上微缩的全节点工艺,它使用智能的微缩主要设计规则(栅极,鳍和MX / Vx的间距)以提高良率,同时他为这个工艺带来了0.021um²的SRAM单元,同时还有一个优于计划的缺陷密度(logic defect density)d 0。
5nm技术平台成功的主要原因是实现了极紫外(EUV)光刻技术。完整的EUV在切割,接触,过孔和金属线掩膜步骤中至少可替代四倍的浸没层,这就能帮助缩短周期时间,提高可靠性和良率。5nm中的总掩模数量比以前的7nm节点少几个掩模。图1显示了一个EUV掩模如何代替五个浸没掩模,又如何产生更好的图案保真度,更短的循环时间和更少的缺陷。

图1. BEOL金属化图,将EUV与浸没光刻法进行了比较,显示了一个EUV掩模如何以更好的图案保真度,更短的循环时间和更少的缺陷取代了五个浸没图案层。
从16nm节点到7nm,FinFET已经使用了四代,但性能一直不受影响。这是因为采用了高移动性沟道(HMC),图2中的TEM显示了与Si晶格常数相接的完全应变HMC晶格常数。衍射图证实了HMC应变。
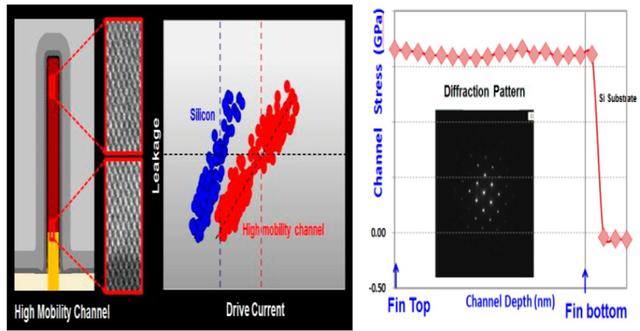
图2. finFET截面TEM的示意图,显示了与Si晶格常数相接的全应变HMC晶格常数。第二个图显示,硅与HMC晶体管的漏电流与驱动电流的关系更大。第三幅图显示了通道应力(以GPa为单位)与从鳍片顶部到鳍片底部的通道深度之间的关系。所示的衍射图证实了HMC应变。
如图3所示,HMC finFET具有出色的Id-Vg特性,并且其产生的驱动电流比Si finFET高出约18%。品质因数(Figure-of-Merit 、FOM)环形振荡器( ring oscillator)的待机功耗也与晶体管泄漏密切相关。
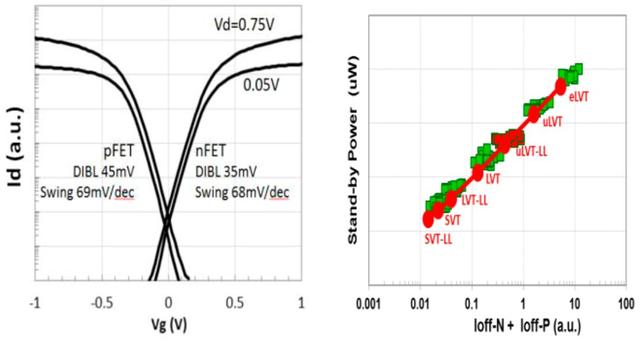
图3.图表显示了对于不同的漏极电压,高迁移率沟道(HMC)晶体管的漏极电流与栅极电压(Id与Vg)的关系。第二幅图显示了该技术中可用的七个不同Vt的截止电流范围Ioff-N和Ioff-P以及对待机电流的相对影响。两个图中的电流均为对数刻度,每格十进制。漏极感应势垒降低(DIBL)为45mV和35mV,对于p沟道和n沟道晶体管,摆幅分别为69mV和68mV。
这种5nm CMOS平台技术是IEDM 2016中描述的7nm工艺的完整节点微缩。每种晶体管类型的最高7 Vt的可用性(如图4所示),这就是使产品设计能够满足移动SoC的功耗效率需求以及HPC的峰值速度要求。
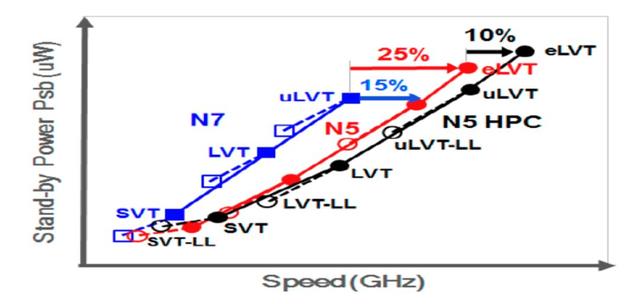
图4. N5中最多可提供七个Vt的图表,显示了N5和N5 HPC与N7相比时的待机功耗(uW)与GHz速度的对比,以满足移动设备的最大功耗效率和HPC的峰值速度。eLVT在7nm处的峰值速度提高了25%。硅数据接近匹配的FOM ring速度与待功耗。
HPC的新功能是极低的VT(eLVT)晶体管,且较之7nm,峰值速度提高25%,并因为采用三个Fin的标准单元,从而可以将性能进一步提高10%。该技术可用于使用混合键合的3D芯片堆叠。除了相比于7nm,获得令人印象深刻的密度和性能提升之外,该技术还获得了1000小时HTOL认证,相对于7nm技术而言,它具有改善的应力老化特性。另外,高良率的SRAM和逻辑缺陷密度D 0超出了计划。能够实现这样的提升,主要倚仗于包括完全实施EUV和高迁移率沟道(HMC)finFET等技术。
设计和开发此5nm平台技术是为了满足PPACT的目标(功率,性能,面积,成本和上市时间)。设计技术协同优化(DTCO)强调了智能缩放,避免了粗暴微缩(rute-force scaling ),因为粗暴微缩会导致工艺成本和产量影响急剧增加。栅极-接触-扩散(gate-contact-over-diffusion)和独特的扩散终止(unique diffusion termination )以及基于EUV的栅极图案等设计功能可降低SRAM的尺寸并提高逻辑密度。与7nm节点相比,5nm在相同功耗下的速度则提高了15%,在相同速度下的功耗降低了30%,且逻辑密度提升了1.84倍,如图5所示。
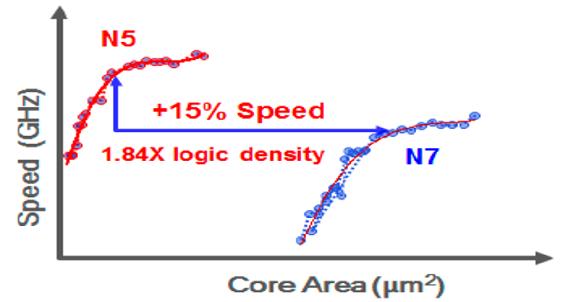
图5.比较N5技术和以前的N7 的速度(GHz)与核心面积(um²)的比较。5nm技术在7nm节点的逻辑密度为1.84倍的情况下,在相同功耗下的速度提高了15%,在相同速度下的功耗降低了30%。
互连延迟会严重影响产品性能,并且每一代互连延迟都会变得越来越差。从N28到N5的世代,后端金属RC和过孔电阻如图6所示。通过EUV图案化,创新的按比例缩放的 barrier/liner ESL / ELK电介质和Cu回流焊(reflow.),最紧密的间距Mx RC和Vx Rc保持与7nm节点相似。
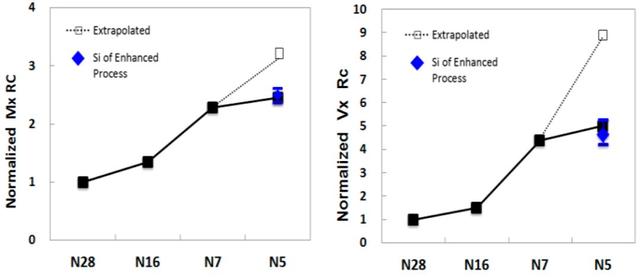
图6.示出了归一化的BEOL金属化RC产品和过孔电阻与节点(从N28到N5)之间的关系图。对于最紧密的金属间距,通过EUV图案化,创新的按比例缩放的势垒/衬里ESL / ELK电介质和Cu回流焊,MX RC和过孔电阻Vx Rc保持与先前的7nm节点相似。
SRAM的密度和性能/漏电对于移动SoC和HPC AI至关重要。SRAM单元更先进节点的缩放更加困难. 所提供的高电流(HC)和高密度(HD)SRAM单元分别拥有0.025um²和0.021um²的面积,这是业界密度最高的器件(如图7)。同时还实现了始终如一的256 Mb SRAM高良率,逻辑测试芯片的峰值良率大于90%,平均良率约为80%(无需维修)。
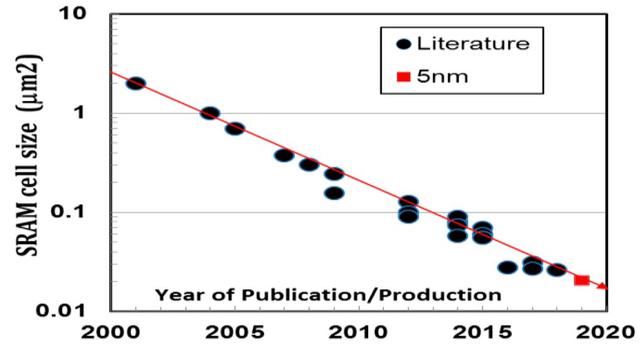
图7. 已发布的SRAM单元的尺寸大小与发布年份的关系图。
超低泄漏ULHD可用于减少保留泄漏,以实现更好的电源效率,而高速HSHD SRAM可替代HC SRAM单元,从而使存储区域减少约22%,如图8所示。
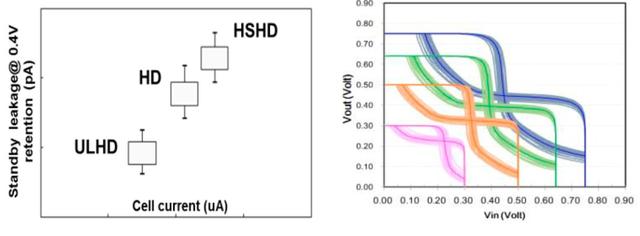
图8. ULHD,HSHD和标准HD SRAM单元在0.4V时的pA待机泄漏与uA中的单元电流的关系图。5nm HD SRAM单元的Vout与Vin蝶形曲线图显示在0.75V至0.3V的电压下。
如图所示,具有完整读/写功能的256Mb 0.021 um ² HD SRAM单元的shmoo plot可低至0.4V。
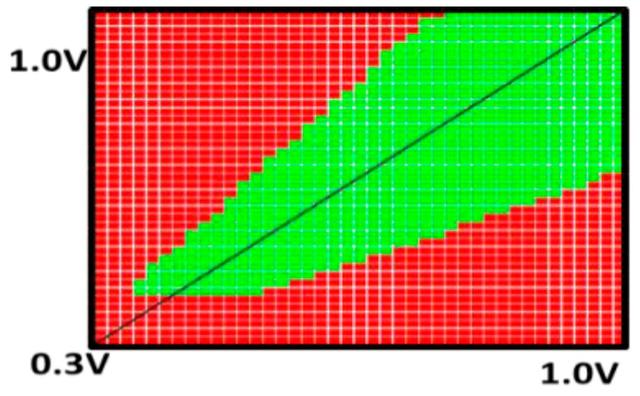
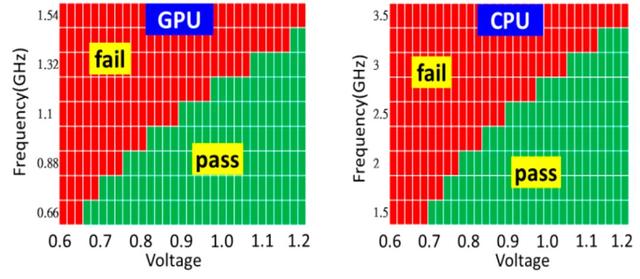
图10显示了高良率逻辑测试芯片中GPU和CPU模块的频率响应shmoo图。
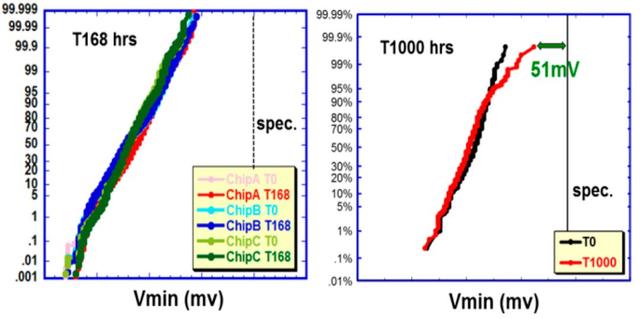
256Mb HD / HC SRAM和逻辑测试芯片通过了1000小时的HTOL认证。SRAM Vmin在168小时时的变化可以忽略不计,并且以约51mV的裕度通过了1000小时的HTOL,如图11所示。
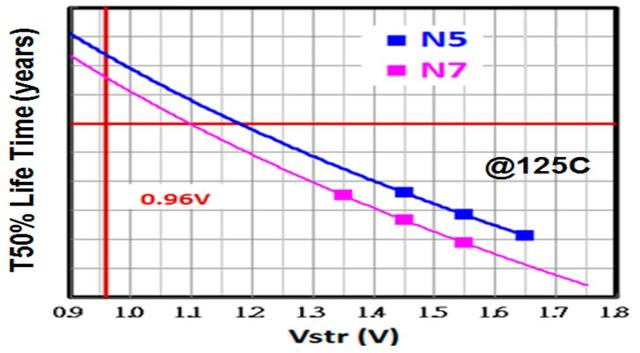
如图12,使用高迁移率沟道FinFET制成的5nm FOM环形振荡器在0.96 V和125C时的应力老化数据(Stress aging data),相对于7nm节点具有更好的表现。
HPC所需的另一个重要功能是在BEOL金属化层的上层中形成的金属-绝缘体-金属(MiM)电容器。5nm节点MiM的电容密度是典型HD-MiM的4倍,并通过最小化瞬态下降电压使Fmax快约4.2%,并在CPU测试芯片中将Vmin降低了约20mV。
HPC严重依赖于高速IO,尤其是SERDES。通过使用特殊的高速设备成功优化finFET驱动强度和电容/电阻。
总而言之,台积电提供了一个极具竞争力的技术平台,确立了其在同类最佳的最高密度逻辑技术领域的领导者地位。2020年上半年的批量生产将使先进的SoC产品在移动设备(尤其是5G)以及用于AI,数据中心和区块链产品的HPC应用中实现领先,这些产品日益需要高性能和最佳能效。
来源:内容由半导体行业观察(icbank)编译自「semiwiki」,作者:Don Draper,谢谢。








