

2023年10月,美商务部更新了针对AI芯片的限制规定,对出口中国的AI算力芯片产品的算力、算力密度、带宽等上限提出了明确要求。受此影响,英伟达(NVIDIA)此前针对中国市场定制的A800、H800,以及此前未受限的众多AI芯片都受到了限制。基于此,NVIDIA随后又为中国市场定制了H20、L20、L2等产品。
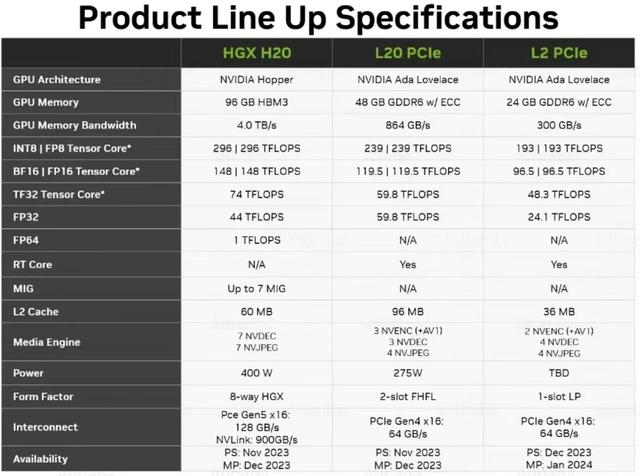
从公布的参数来看,H20的FP16、INT8等主要算力参数仅为A100的不足1/2,更是仅为H100的约1/7;L20的主要算力参数相较于L40、L40S分别下降约1/3、2/3。这些最新的针对中国市场定制的产品算力参数被大幅阉割,使得市场大多对其性能表现、性价比(1.2-1.4万美元,略低于Ascend 910的约。1.66万美元)持悲观或怀疑态度。
在此前的《关于英伟达H20砍单传言》一文当中,NVIDIA内部人士虽然承认,然经过阉割后的NVIDIA H20单卡算力仅有H100的20%,相比国产的910b,性能也只有其60%多。但是,其强调,H20仍有两大优势:
1、H20的HBM容量(96GB)与带宽远比910B高(也高于A100/H100的80GB HBM3),带宽是910B两倍。
2、NVIDIA有NVlink架构。H20可以是通过多卡使用、多卡堆叠模式,完全超越910B,甚至突破H100。
同时,该内部人士还表示,H20的中国订单一直稳定,市场部尚未接到大量砍单的现象。
不过,这一与外界看法相悖的说法,依然是没有消除外界的疑虑。那么,H20在被阉割之后,究竟还有多少优势?
近日,广发电子团队基于理论计算,研究了H20、L20等产品在大模型推理端的性能表现。推算结果显示,H20、L20均展现出较优异的推理性能。
以下为主要内容:
1根据推算,H20推理性能超过H100,L20推理性能比肩L40S
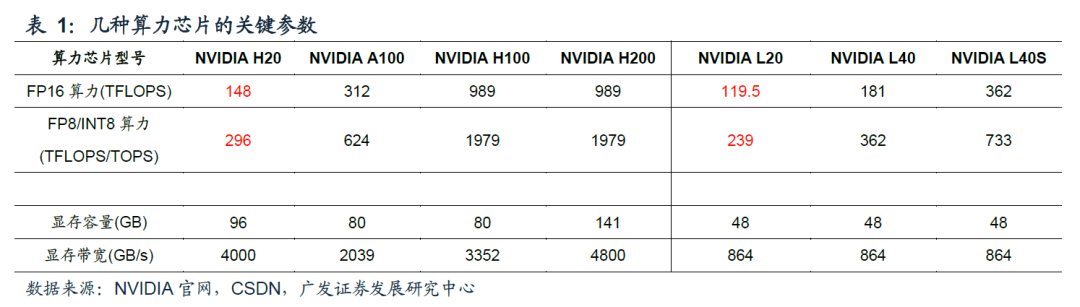
H20推理性能优于A100、H100,仅略逊于H200。分别使用单张H20、A100、H100、H200进行推理。参考图1,在3组推理场景下,H20的推理速度均明显优于A100;在前两组推理场景下,H20的推理速度优于H100,第三组推理场景下H20与H100推理速度基本持平。取三组平均值,H20平均推理速度是A100的1.8倍,是H100的1.1倍。
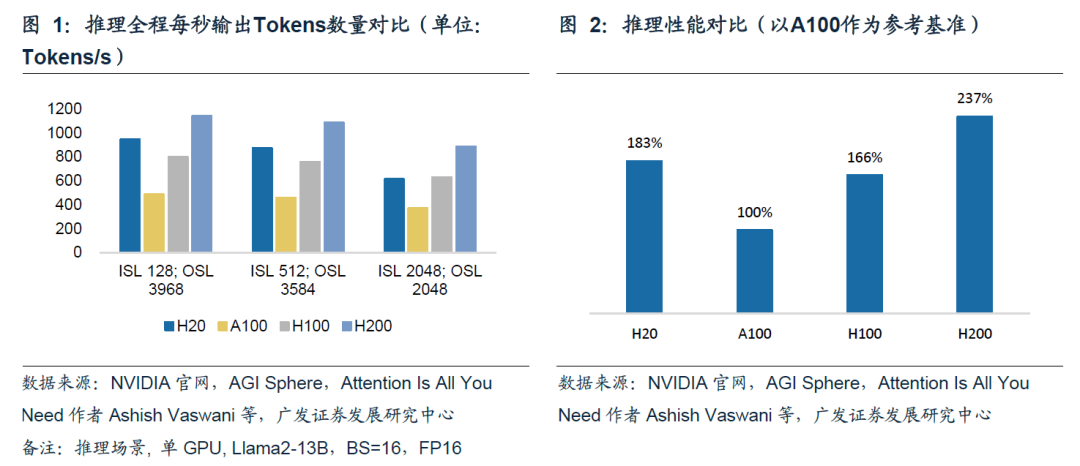
L20推理性能与L40、L40S基本相同。分别使用单张L40S、L40、L20进行推理。参考图3,在前两组推理场景中,L40S、L40、L20的推理速度无明显差异;仅在最后一组场景中,L40S推理速度相较于L40、L20优势较明显。取三组平均值,L20推理速度仅比L40S速度慢约2%。
为什么算力被大幅阉割的H20会有如此优异的推理性能表现?在接下来的两个章节,广发电子分别分析了推理过程中Prefill环节、Decode环节H20的推理性能表现。
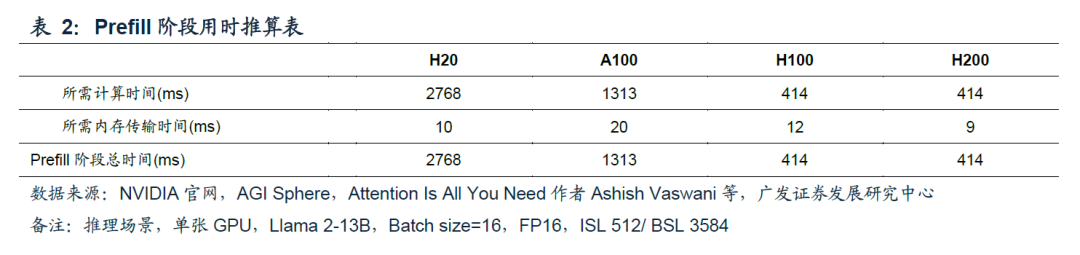
Prefill阶段算力负载体现在对用户所有输入Tokens进行一次并行计算;显存带宽负载主要体现在参数量从HBM向算力芯片的传输。在大多数推理场景下(如输入Tokens较长、或Batch Size较大),Prefill阶段计算耗时高于显存传输的耗时,因此该环节的耗时(也被称为First token latency)通常是由算力芯片的算力能力决定,Prefill阶段属于算力密集场景。
参考表2,由于H20的算力较弱,在Prefill环节H20耗时明显高于其他三款芯片。这也意味着在使用H20进行推理时,用户从完成问题输入、到看到问题第一个文字的输出,中间需要等待较长时间。
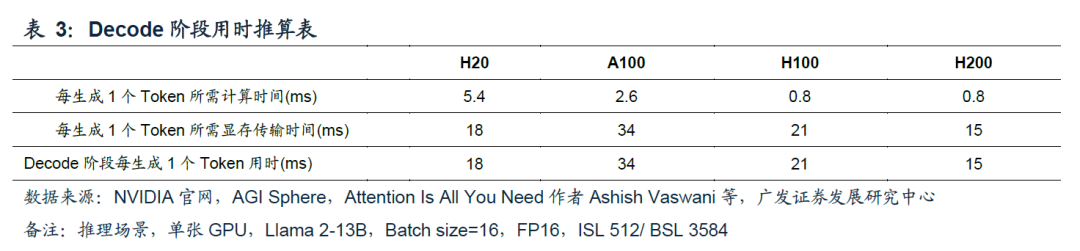
在Prefill阶段结束后,大模型开始生成回答,该过程被称为Decode。由于Decode过程中,回答的Tokens必须逐个生成,且每个Token生成过程中,都需要重复一次参数从HBM向算力芯片的传输,且Decode阶段不断扩大的KV Cache也需要在HBM和算力芯片间往复传输,使得Decode阶段通常显存传输耗时明显高于计算耗时;Decode阶段属于显存带宽密集场景,更高的显存带宽对加速Decode至关重要。
参考表3,由于H20具有较高的显存带宽,在Decode阶段H20每生成1个Token所需时间低于A100、H100,这也使得H20在整个推理过程具有较高的推理速度。
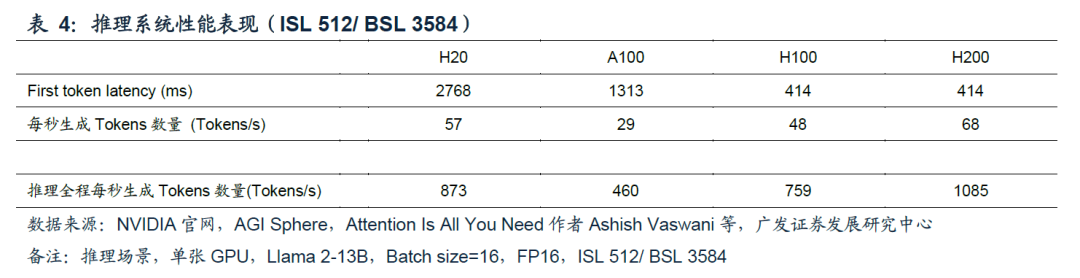
多数应用场景下,站在H20推理使用用户角度,在输入问题后,等待界面出现第一个回答文字的等待时间会较长(相较于使用A100/H100/H200进行推理),但考虑到这一时长也仅为2.8s,对用户使用体验的负面影响是有限的。(备注:实际用户等待时间还包括网络延迟、用户端侧延迟等)
而在回答开始后,使用H20的用户会体验到回答生成速度较快(相较于使用A100/H100进行推理),每秒57个Tokens的生成速度明显高于人类阅读速度。
站在H20持有人角度,持有人更关心一个推理系统Throughput的速度,因为对相同一套推理系统或成本相近的不同推理系统,平均Throughput(Tokens/s)越高,意味着每Token所平摊的系统硬件成本越低。从性价比角度看,假设H20与H100售价相近,在多数情况下,H20也有望成为性价比更高的推理芯片选择。
以上关于H20优异的推理性能的分析,是建立在较常见的推理场景(回答文字大于等于提问文字),在一些特殊推理场景下,例如输入一段长文字并输出长文字核心观点(对应较长的输入和较短的输出),参考表5,站在用户角度,从输入问题到出现答案的耗时会较为漫长(超过20s);站在持有人角度,推理全程H20的推理速度会下降至明显低于A100。
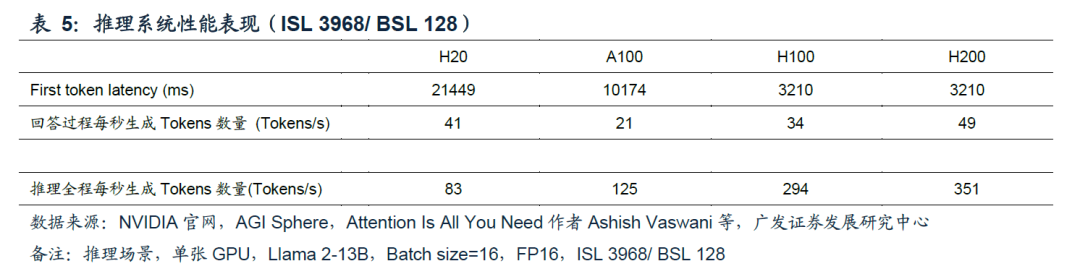
因此,广发电子认为H20的推理性能优异、推理性价比高,适用于大部分推理场景,而非全部场景;H20实际的推理性能及性价比,需要结合实际使用场景、售价等综合评判。
编辑:芯智讯-浪客剑 资料来源:广发电子







