
从计算机诞生起,计算机系统就是在冯·诺依曼架构下运行。在冯·诺伊曼架构中,计算与内存是分离的,计算单元从内存中读取数据,计算完成后再存回内存。特别是随着人工智能等对性能要求极高的场景爆发,传统的冯·诺依曼架构的短板开始凸显,例如功耗墙、性能墙、内存墙的问题。
造成这一问题的原因主要有两点:
一是数据搬运带来了巨大的能量消耗。数据显示,在传统架构下,数据从内存单元传输到计算单元需要的功耗是计算本身的约200倍,因此真正用于计算的能耗和时间其实占比很低。
二是内存性能的发展远远滞后于处理器的发展。目前,处理器的算力以每两年3.1倍的速度增长(AI对于算力的需求每两年提升750倍),能够处理器的数据量也快速增长,但是内存的性能每两年只有1.4倍的提升。
也就是说,即使处理器每秒能够处理3.1倍的数据量,但是由于处理器从内存中存取数据都是经过同一条内存总线访问,而这个内存总线如果最多只能通过1.4倍的数据量,这也意味着处理器也只能处理1.4倍的数据量。内存性能限制了处理器性能的提升。
目前内存性能的提升速度严重滞后于处理器性能提升的速度,这就好比一个漏斗,宽的一端是处理器,而狭窄的一端则是存储器,后者的性能极大地影响了数据传输的速度,这也被认为是传统计算机的阿克琉斯之踵。这一点在AI/HPC计算领域尤为明显。
因此,目前众多的芯片巨头都有在研究存内计算(Processing-in-memory,PIM)芯片,在2021年12月,阿里巴巴旗下达摩院计算技术实验室成功研发全球首款基于DRAM的3D键合堆叠存算一体AI芯片,号称在特定AI场景中,该芯片性能提升10倍以上,能效比提升高达300倍。此外,三星、SK海力士等存储芯片大厂也在研究PIM芯片。在不久前的Hot Chips 2023会议上,三星、SK海力士也分别披露了其PIM芯片的最新进展。
三星的存内计算/近存计算布局
其实早在2021年Hot Chips会议上,三星就公开针对Facebook 的DLRM(Deep Learning Recommendation Model)模型的AXDIMM(Acceleraton DIMM)、LPDDR5-PIM 及代号Aquabolt-XL 的HBM2-PIM,披露了完整技术布局。

▲利用PIM可以一劳永逸解决内存瓶颈
在不久前的Hot Chips 2023会议上,三星进一步扩展存内计算范围至CXL(Compute eXpress Link)外部内存储存池。下面我们就来看看三星对存内计算的观点与看法。
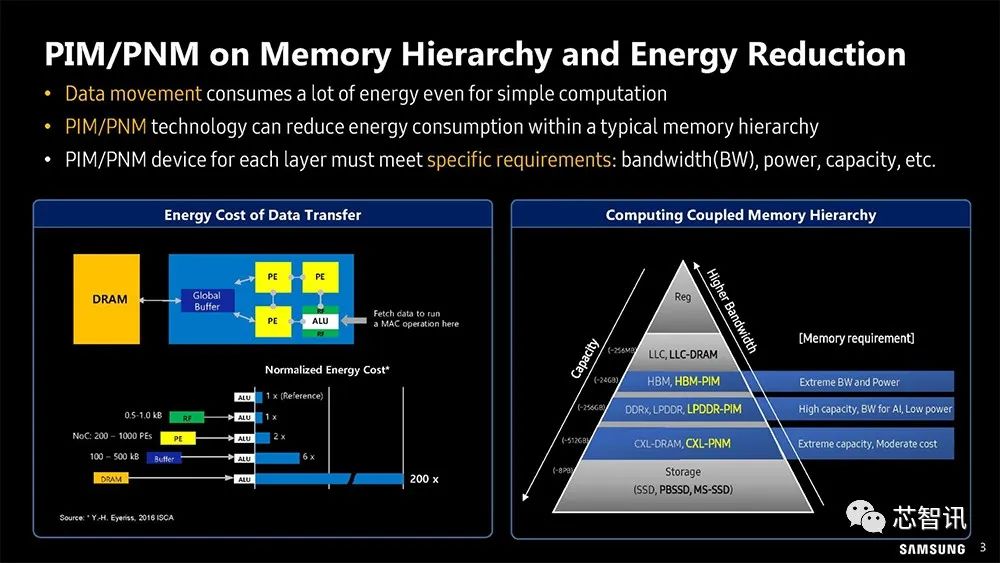
▲计算工作最昂贵的成本之一:将数据从不同储存位置和内存空间,搬运到实际计算单元。
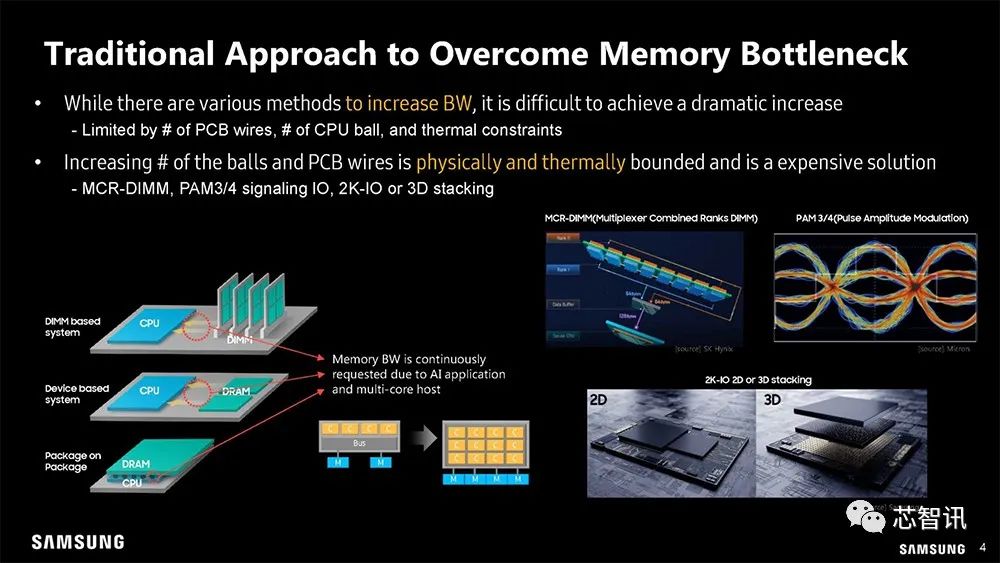
▲ 通过增加内存通道或提升内存工作频率的传统手段,有物理局限性。
比如会受到PCB导线数量、CPU封装的植球数量是受物理和热限制的,一种昂贵的解决方案是——MCR-DIMM、PAM3/4 信号l/O、2K-IO或3D堆叠。
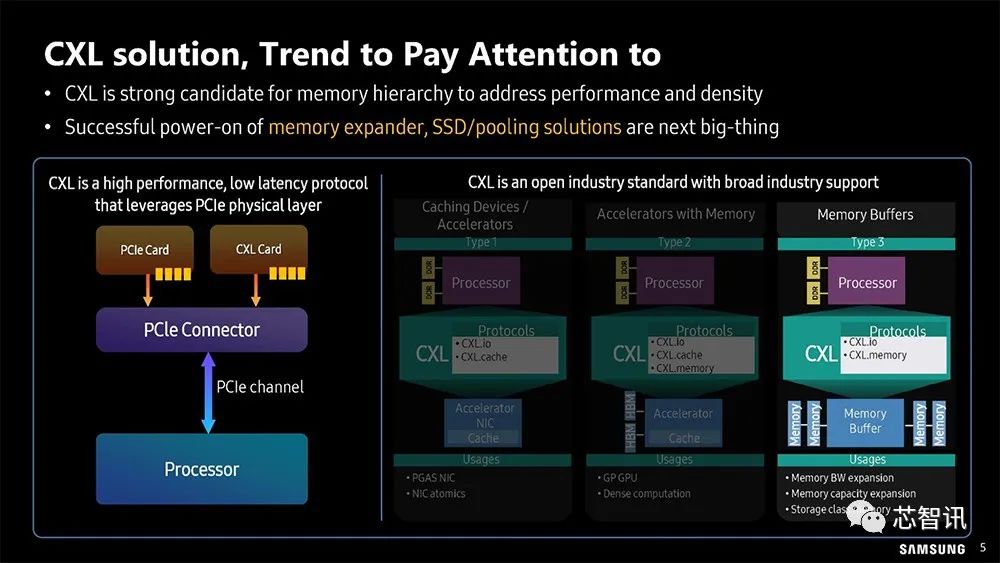
▲ 所以三星也开始将注意力放到了以PCIe 为基础的CXL方案了。
CXL (Compute Express Link) 技术是一种新型的高速互联技术,旨在提供更高的数据吞吐量和更低的延迟,以满足现代计算和存储系统的需求。它最初由英特尔、AMD和其他公司联合推出,并得到了包括谷歌、微软等公司在内的大量支持。
CXL的目标是解决CPU和设备、设备和设备之间的内存鸿沟。服务器有巨大的内存池和数量庞大的基于PCIe运算加速器,每个上面都有很大的内存。内存的分割已经造成巨大的浪费、不便和性能下降。CXL是解决性能和密度问题的内存层次结构的有力候选者。成功开启内存扩展器、SSD/池化解决方案将是下一件大事。
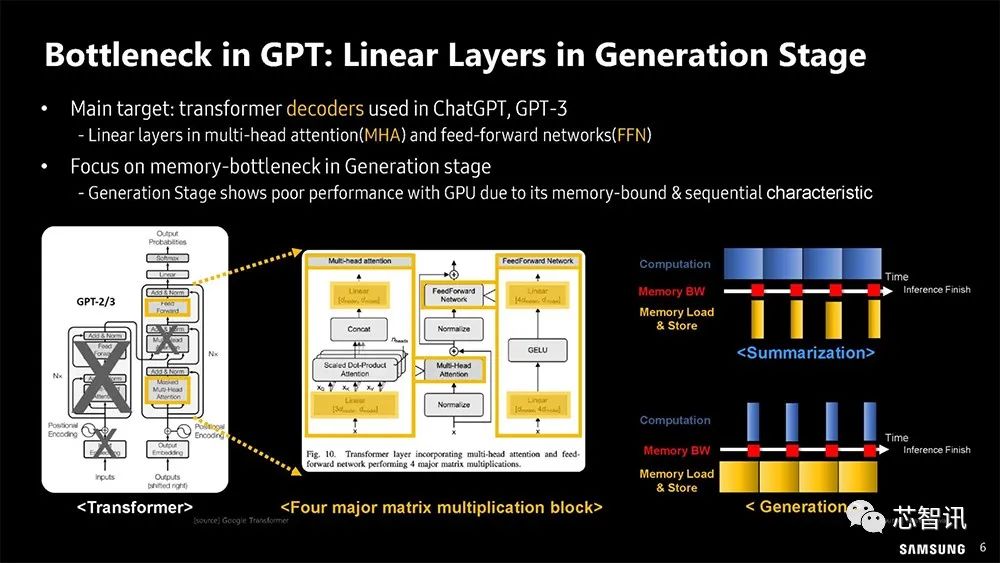
▲ChatGPT-3 的内存瓶颈。
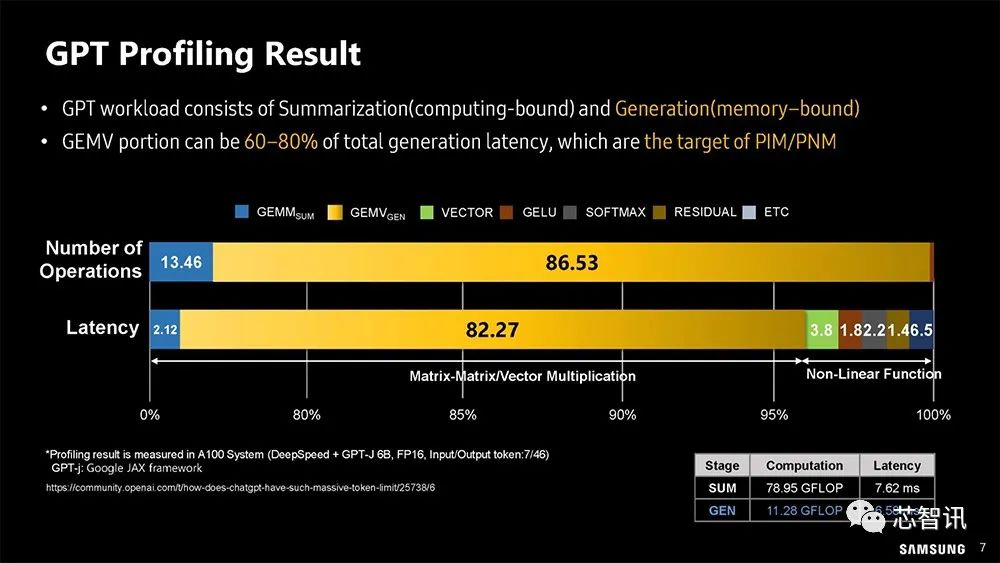
▲三星分析ChatGPT 的工作负载
GPT工作负载由汇总(计算绑定)和生成(内存绑定)组成。大规模矩阵向量运算(GEMV)部分可能占总生成延迟的60-80%,这正是PIM/PNM(Processing Near Memory,近存计算 )的目标。
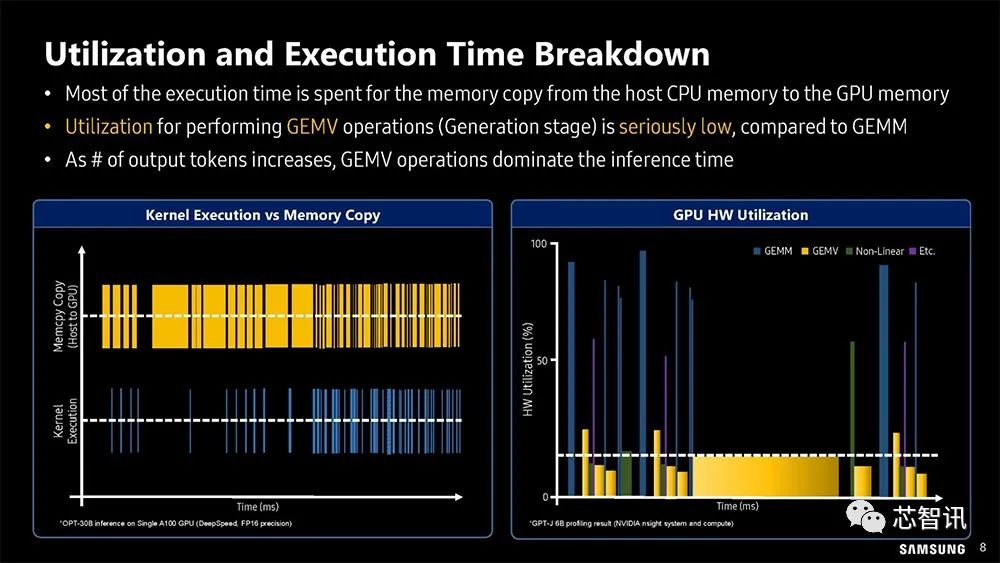
▲GPU 利用率分析,多数执行时间都浪费在资料于CPU 与GPU 间反覆搬运。
通过对利用率和执行时间细分,大部分执行时间都花在从主机CPU内存到GPU内存的数据复制上。与广义矩阵乘积操作(GEMM)相比,执行大规模矩阵向量运算(GEMV)操作(生成阶段)的利用率非常低。随着输出令牌数量的增加,GEMV操作占据了推理时间的主导地位。
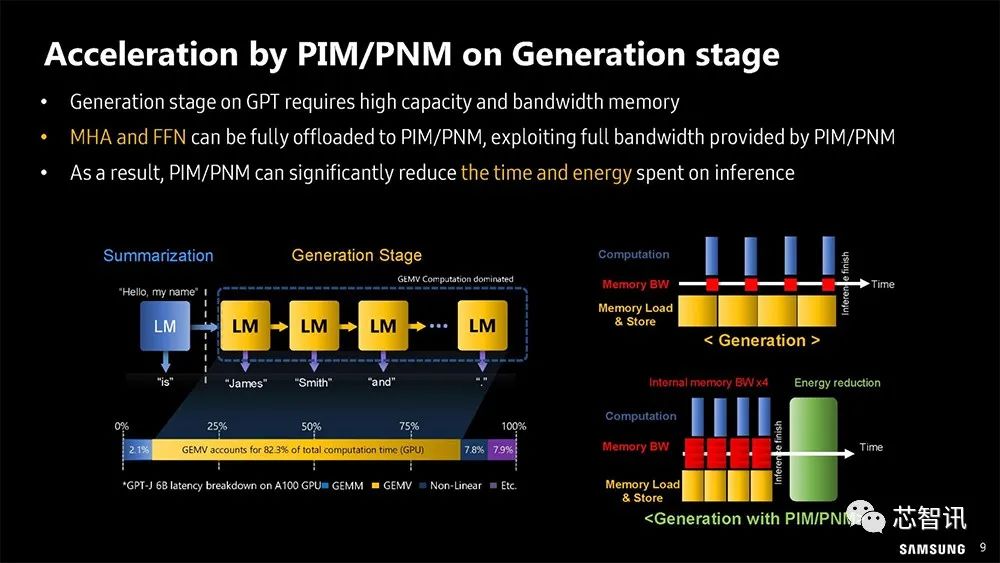
▲三星展示在GPT加速方面如何将部分计算卸载至存内计算处理(PIM)。
Multi-Head Attention (MHA) 和Position-wise Feed-Forward Network (FFN)可以完全卸载到PIM/PNM,利用PIM/PNM提供的全部带宽。因此,PIM/PNM可以显著减少推理所花费的时间和精力

▲直接进行存内计算,可减少数据搬运,降低功耗和互连成本。
三星表示,由于OpenAl专注于开发新的Al技术,并突破Al的极限,他们很可能会在未来探索PIM技术的使用。在lSSCC 2023中,AMD也提到,关键算法内核可以直接在内存中执行,可节省宝贵的通信能耗,与传统的HBMS相比,PIM可以减少85%的能耗。
1、HBM-PIM
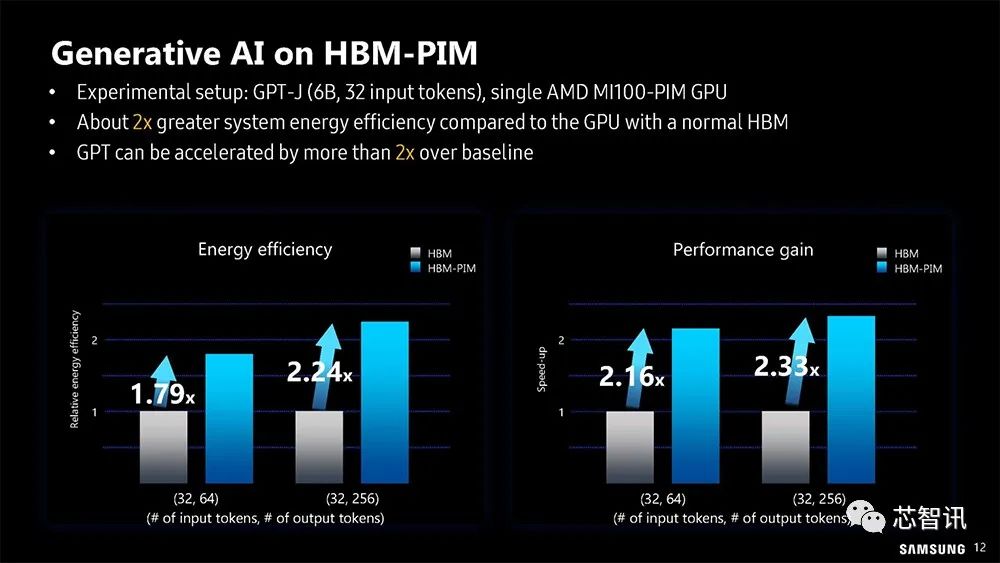
▲生成式AI在三星的HBM-PIM上的表现
实验设置:GPT-J(6B,32个输入令牌),单个AMD MI100-PIM GPU
与配备传统的HBM的GPU相比,生成式AI运行在基于三星的HBM-PIM的系统上,能效平均高出了约2倍,性能加速了2倍以上。

▲三星2022 年底用96 张基于HBM-PIM改造后的AMD MI100 加速卡,建设了全球第一个基于PIM 的GPU 运算系统,以高能效和低延迟加速大规模工作负载。

▲T5(Transformer)-Based MoE模型如何使用HBM-PIM集群。
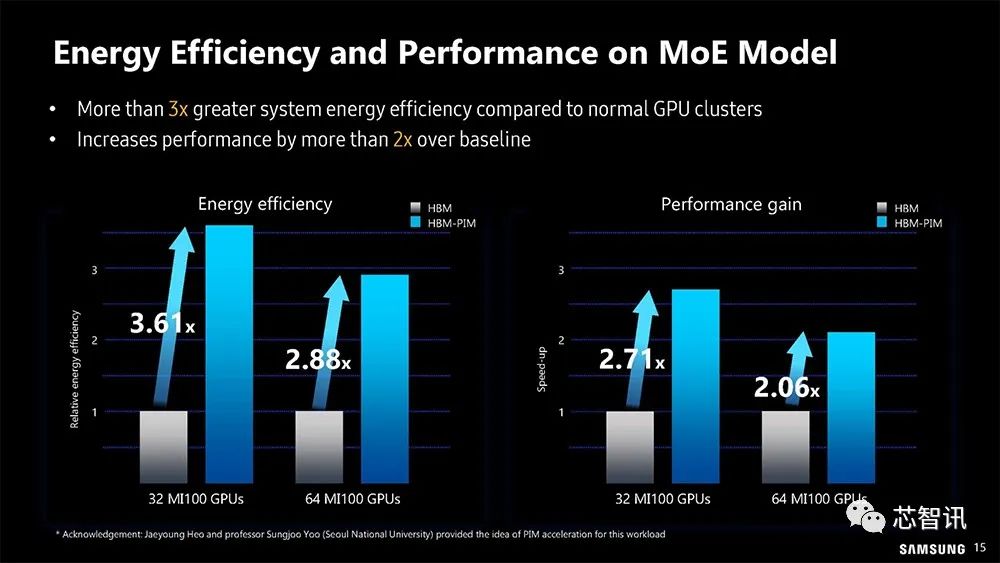
▲可以看到,基于HBM-PIM集群的MoE模型的能源利用效率和性能与普通GPU集群相比,系统能效提高了3倍以上,性能比基线提高了2倍以上。
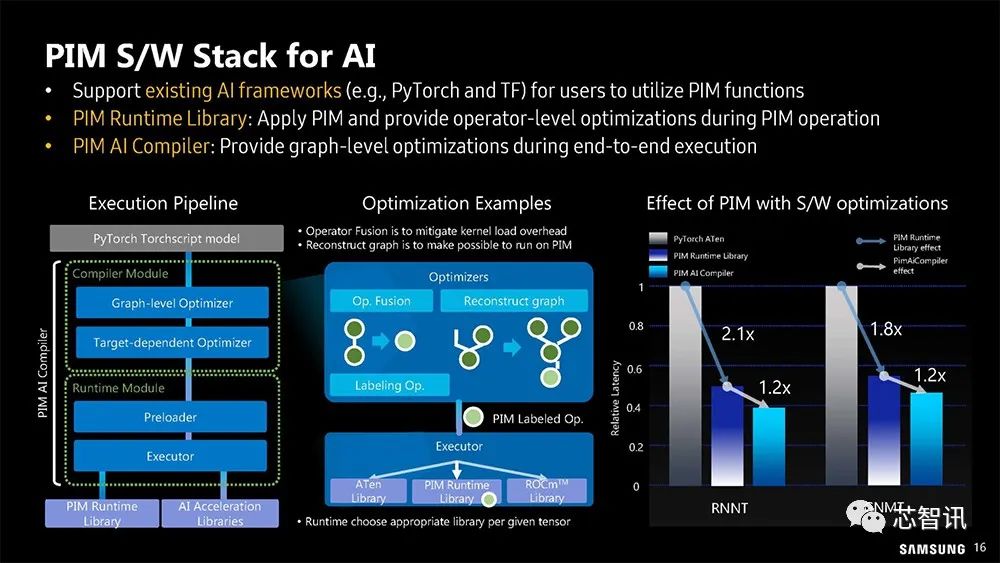
▲但AI计算的关键还是在软体如何有效运用PIM。
比如,支持现有的Al框架(例如PyTorch和TF),供用户使用PIM功能;提供PIM运行库,在PlM操作期间应用PlM并提供操作员级优化;提供PIM Al编译器,在端到端执行期间提供图形级优化。

▲三星希望能将软件环境整合至标准应用程序编程模型
PIM-SYCL加速了异构平台上即将推出的HPC/Al应用程序。SYCL支持现代C 模板中的CPU/GUP/NPU/FPGA。
PIM OpenACC正在为传统科学应用程序开发中。OpenACC支持C/Fortran串行代码的增量并行化。

▲ OneMCC 软件标准的未来计划,但还不是现在。
OneMCC(Memory Coupled Computing,内存耦合计算)是PIM、PNM、CXL解决方案的软件开放标准。计划提供标准编程模型以支持多体系结构和域。可以使用各种加速器(如CPU、GPU和NPU)提升Al和HPC工作负载。
2、LPDDR-PIM

▲除了面向数据中心的HBM-PIM,三星也有面向终端装置(On-Device)的LPDDR-PIM,生成式AI正在进入终端设备。
三星表示,由于对云Al的需求不断增长,数据中心的成本和功耗正在增加。随着敏感数据被传输到云端进行处理,隐私问题也在增加。网络连接并不总是可靠或可用的,尤其是在偏远地区。因此,扩展设备端的Al非常有必要性。其LPDDR-PIM还可通过防止仅为带宽而过度配置内存来提高电池寿命。

▲LPDDR-PIM的表现
据三星介绍,相比传统的DRAM方案,其LPDDR-PIM可以带来系统性能提高4.5倍和72%的功耗节省。比如,通过多组并行操作,可以利用高达8倍的DRAM带宽;利用PIM单元也可以减少大量数据移动带来的功耗。

▲三星LPDDR-PIM基本资料
三星LPDDR-PIM的峰值频宽高达102.4GB/s,使用Bank级并行处理,带宽是基本LPDDR DRAM产品的8倍;
支持本机整数/浮点运算和逻辑(和/或/..)操作;
运算峰值性能:102.4 GFLOPS/s(FP16)、204.8 GOPS/s(INT8);
加速目标:内存受限操作,如BLAS1和BLAS2;
三星可以支持LPDDR-PIM模拟器包来测量性能增益和能耗降低。
因为运算就在PIM芯片内完成,无须将数据传输回CPU 或其他辅助处理器(xPU),所以可大幅降低功耗。
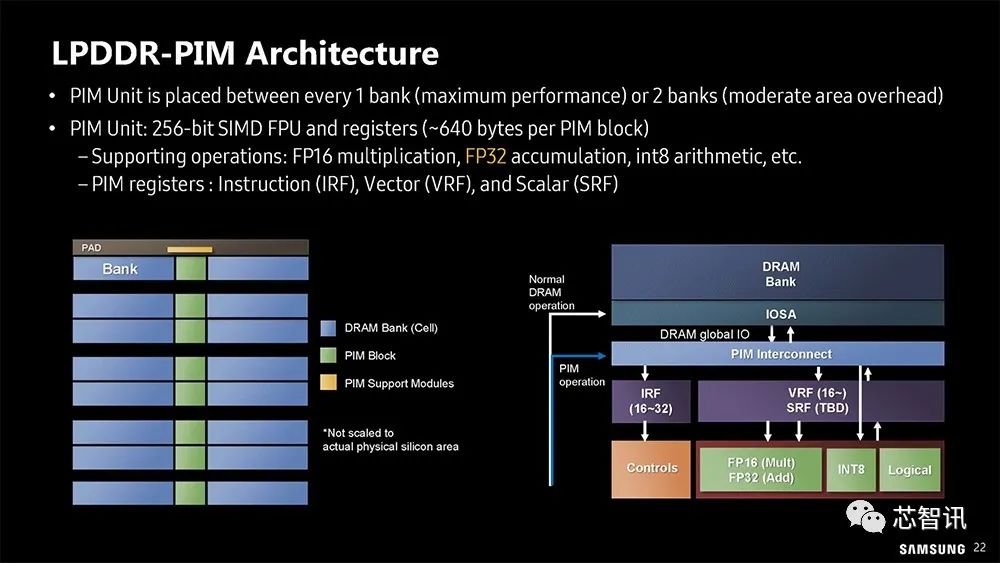
▲三星LPDDR-PIM 架构
PIM单元放置在每1个组(最大性能)或2个组(中等区域开销)之间。
每个PIM单元拥有256位SIMD浮点运算器(FPU),可支持FP16乘法、FP32累加、int8算术等。同时还拥有PIM寄存器,可支持指令(IRF)、矢量(VRF)和标量(SRF)处理。
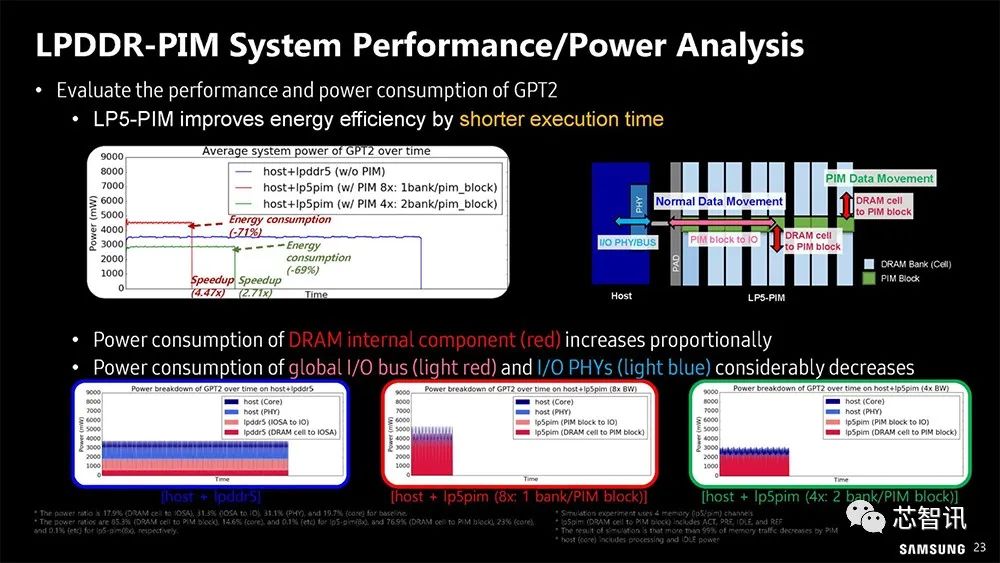
▲ LPDDR5-PIM 性能和功耗分析(基于GPT2)。LPDDR5-PIM可以通过缩短执行时间提高能效。
3、CXL-PNM

▲ HBM-PIM 和LPDDR-PIM 还不够,三星也企图延展到CXL-PNM(Processing-Near-Memory)。
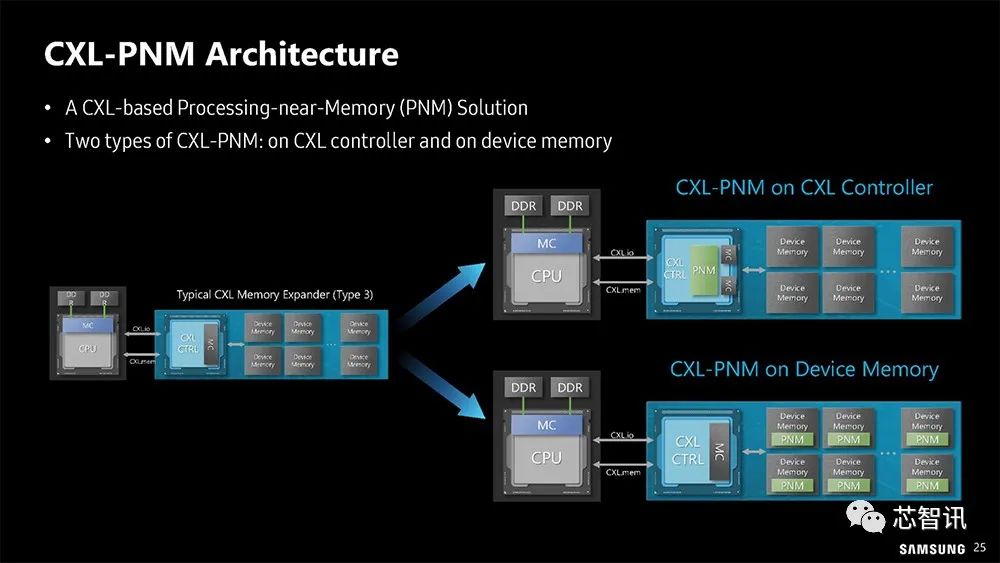
▲ CXL-PNM 有两种方法:运算单元集中放在CXL 控制器,或分散到内存颗粒。

▲用于GPT的CXL-PNM体系结构
PNM引擎上的异构计算单元(PE阵列和加法器树):设计用于执行GEMV操作的加法器树(生成阶段),用于加速GEMM操作的PE阵列(汇总阶段)。

▲ 三星推出CXL-PNM 概念卡,能够用于更广泛的系统,包括Al/ML加速器
与其他解决方案相比,CXL-PNM可以在容量、带宽和功率之间进行独特的权衡。三星的CXL-PNM概念卡可提供512GB容量和1.1TB/s理论带宽。
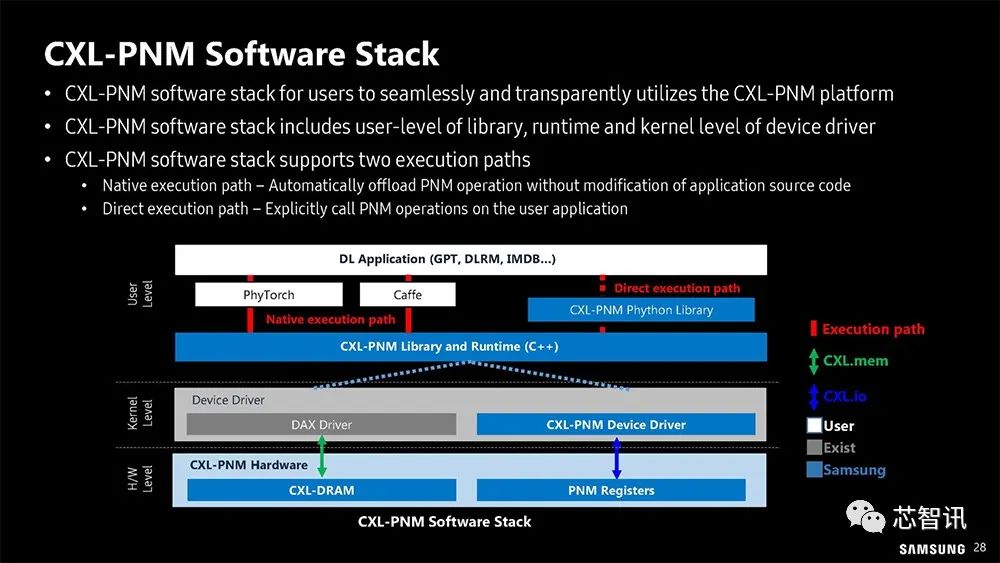
▲ CXL-PNM 也需要专用的软件堆叠架构。
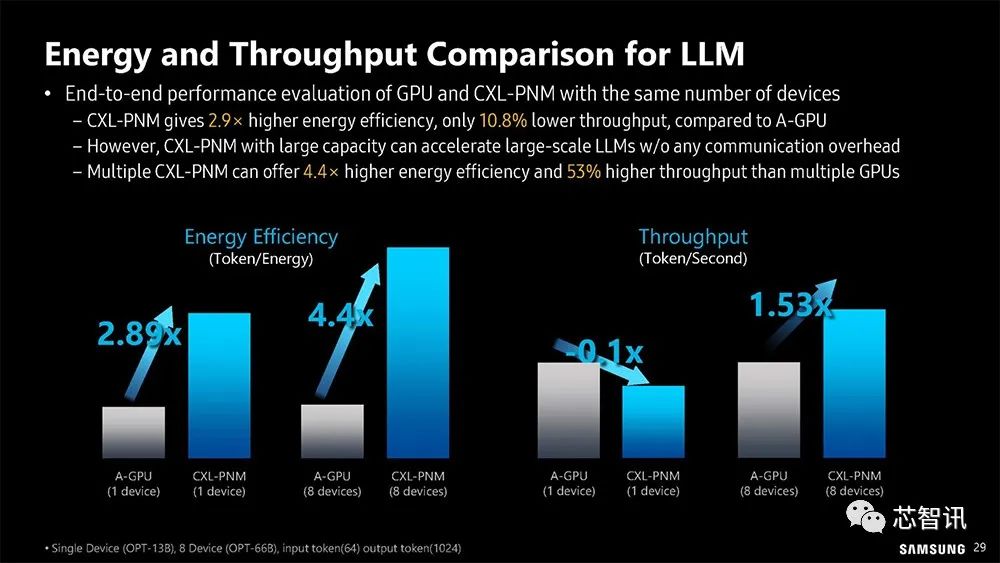
▲大型语言模型引进CXL-PNM 的预期节能和吞吐量
使用相同数量的设备对GPU和CXL-PNM进行端到端性能评估与A-GPU相比,CXL PNM的能效提高了2.9倍,吞吐量降低了10.8%。然而,具有大容量的CXL-PNM可以在没有任何通信开销的情况下加速大规模LLM——多个CXL-PNM可以提供比多个GPU高4.4倍的能效和53%的吞吐量。
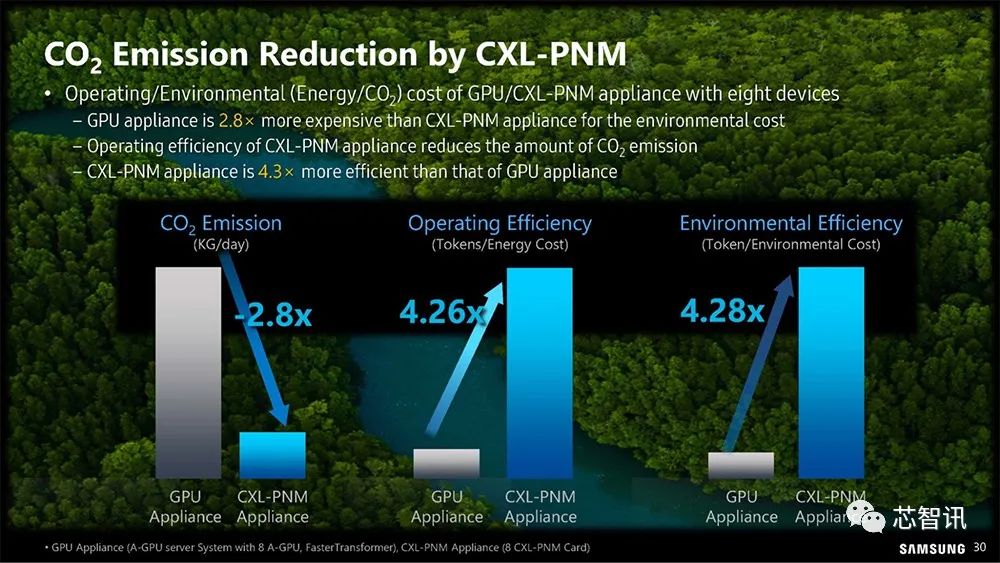
▲毫无疑问,CXL PNM可以减少能源消耗,可以节能减碳。
八个基于GPU/CXL-PNM设备的操作/环境(能源/公司)成本比较:GPU设备的环境成本是CXL-PNM设备的2.8倍,CXL-PNM设备的运行效率降低了二氧化碳的排放量。CXL-PNM设备的效率是GPU设备的4.3倍。
SK海力士的存内计算布局
除了三星之外,另一大内存芯片大厂SK海力士也在Hot Chips 2023会议上公布了其在内存计算方面的布局。
SK海力士认为,在生成式AI的推动下,数据中心需要的不只内存,还需要内建计算功能的特定应用(Domain-Specific)内存,需要将大量计算工作直接放到内存内搞定。
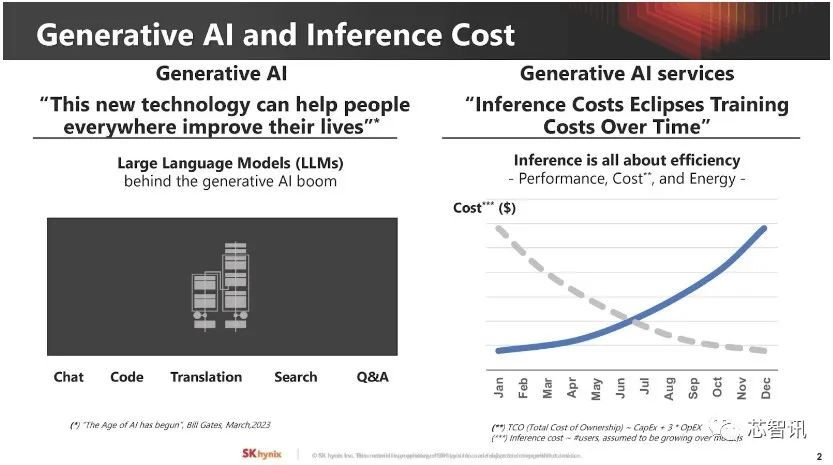
▲ 以大型语言模型为主的生成式AI形成巨大“推理成本”。
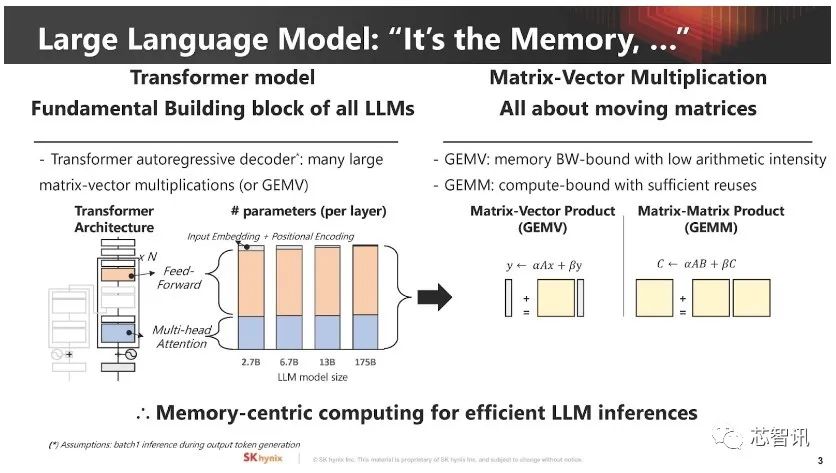
▲ 大型语言模型通常受内存容量和带宽限制,假如能将大型向量矩阵乘积和运算直接交给内存处理,问题就可减轻大半。

▲SK海力士认为根据不同应用,市场需要多种类记忆体技术,一般运算DDR5、移动装置需要LPDDR5、绘图应用GDDR6 和AI训练需要HBM3、外部内存储存池CXL,还得加上内建计算能力、适用生成式AI 与大型语言模型的AiM(Accelerator-in-Memory,内置加速器的内存)

▲所以在Hot Chips 2023会议上,SK 海力士重点介绍了其AiM。

▲这是SK海力士在其GDDR6内存中内建16 个主频1GHz运算处理单元(PU,Processing Unit)的4Gb 颗粒试验品,可处理BF16数据格式,每个Bank都有配置专属PU 以达到完全Bank平行度,内部带宽512GB/s,理论计算吞吐量512G Flops。
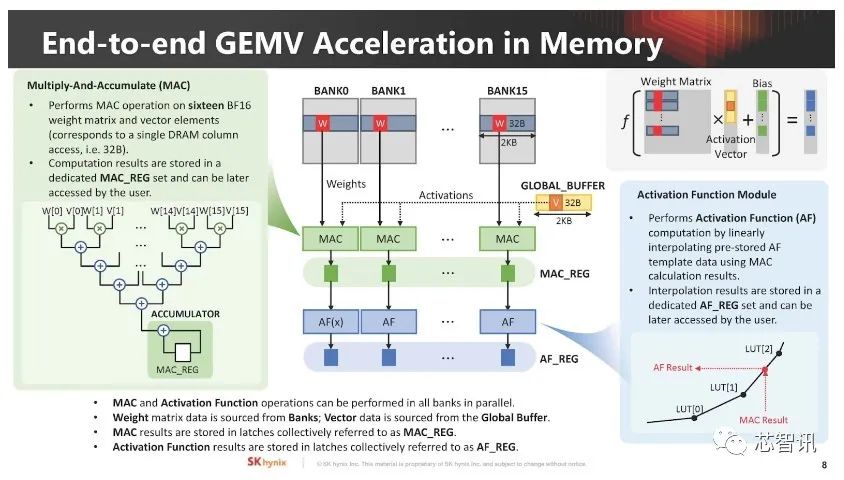
▲ SK 海力士介绍如何在存内执行AI GEMV 计算(16 个BF16 格式的权重矩阵和向量元素),权重矩阵来自Bank,向量数据则出自全局缓冲区。
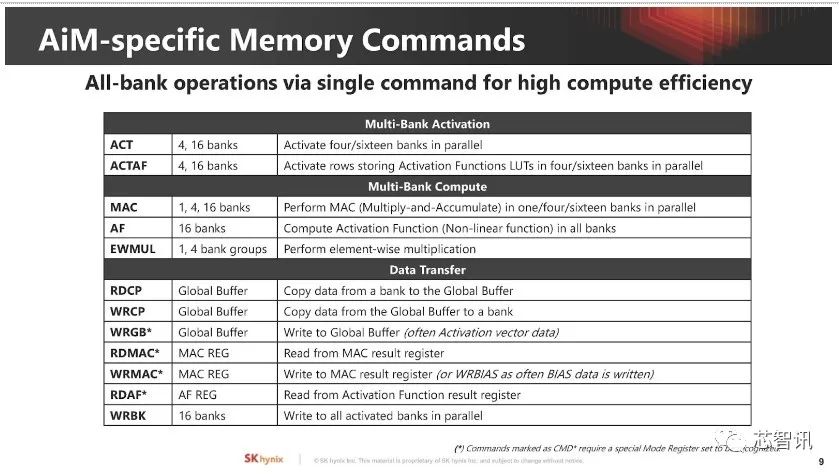
▲存内计算的控制命令。

▲大型语言模型的内存扩展方式及AiM计算资源需求。

▲ 这是AiM 大型语言模型横向扩展方式,由小到大,由内存颗粒到整个系统。
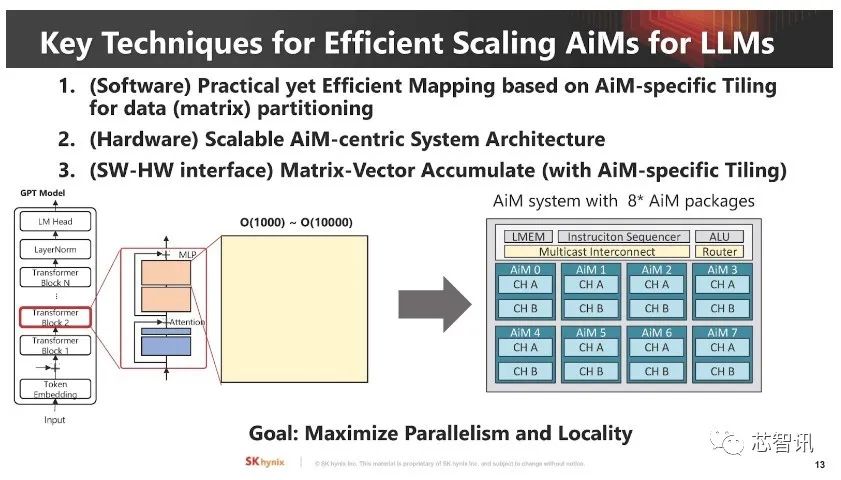
▲ 最大难题还是“软件要怎么运用有计算能力的内存”。
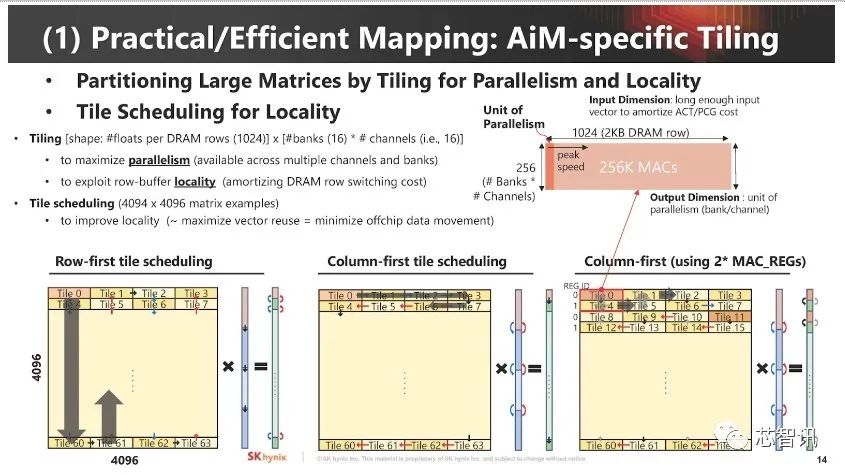
▲ 如何将运算需求“映射”到内存内的执行单元。
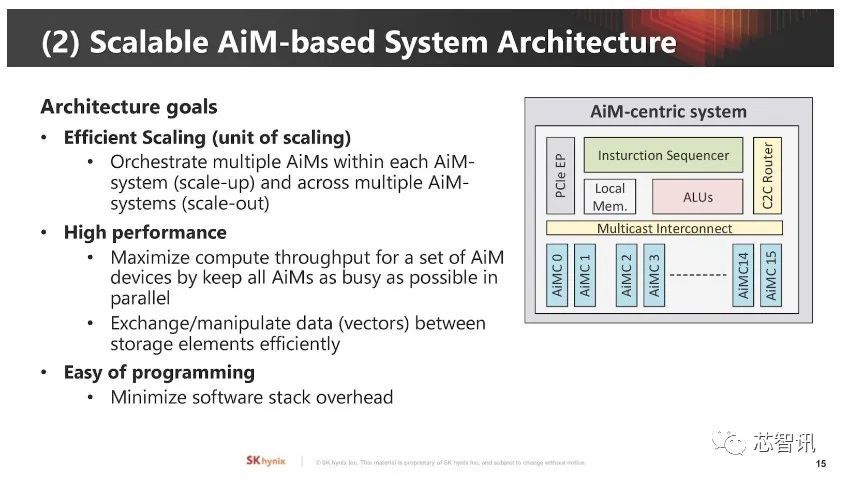
▲ 系统架构同时需要纵向(Scale-Up)和横向扩展(Scale-Out)。
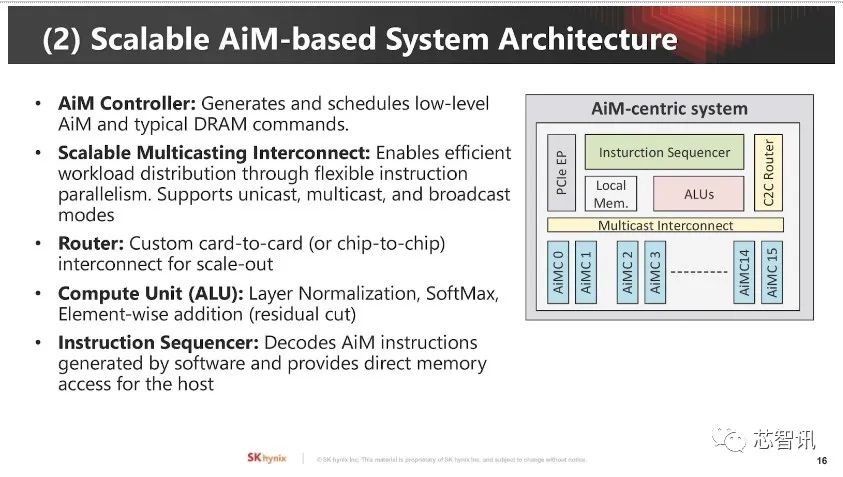
▲AiM 架构的关键元件含AiM 控制器、可扩展式多播(Multicast)互连、路由器、计算单元及指令排序器。
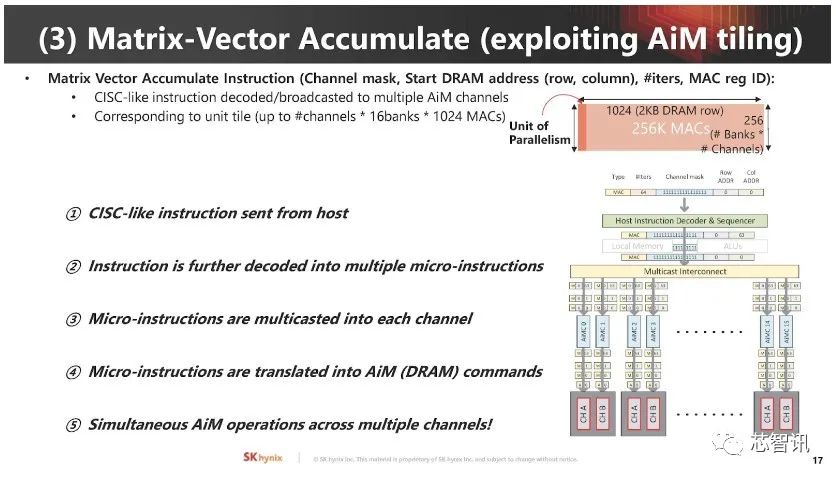
▲矩阵向量累加运算是AI工作关键,AiM 使用类似CISC 指令集管理这些运作。

▲对新的计算架构来说,通常可利用细微最佳化手段使其表现更好。
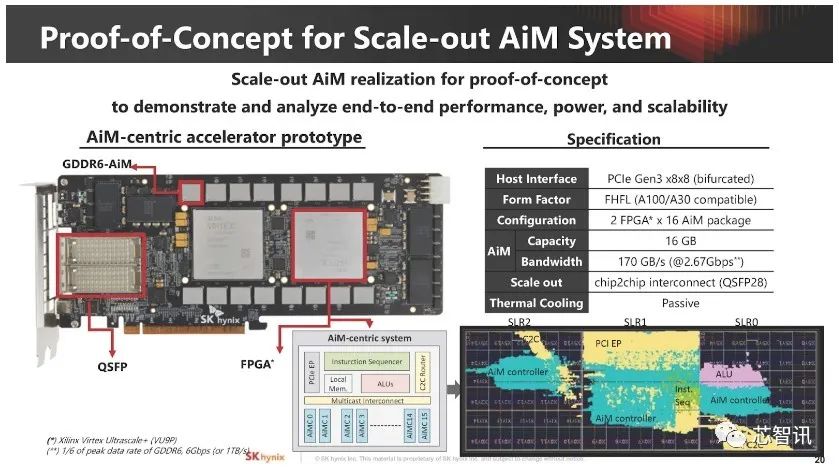
▲SK海力士不仅介绍了其AiM,还展示了4Gb GDDR6-AiM 样品照片,并进一步使用两个赛灵思(AMD)FPGA 构建了技术验证平台。

▲AiM的软件堆叠架构。

▲SK 海力士使用这些软硬件验证概念可行性。

▲SK海力士的AiM仍处于技术评估阶段,并分析适用场景和解决方案。
小结:
随着AI对于算力需求的越来越大,传统的计算架构及内存带宽已经成为了制约的主要瓶颈,在此背景之下,存内计算/近存计算成为了一个重要的突破方向。特别是随着三星、SK海力士等内存大厂的积极推进,存内计算/近存计算将有望加速走向商用。
编辑:芯智讯-浪客剑 来源:综合自servethehom



