
Nvidia和谷歌是AI领域的两大巨头:Nvidia定义了GPU,并以此为基础,2020年凭借 A100 GPU主导了 AI 加速器市场,在人工智能软硬件领域一骑绝尘;谷歌创造了丰富和领先的AI应用,它以ALphaGo出圈,并于2016 年推出TPU芯片,加入了硬件的竞争。
近期,谷歌研究团队发表了新论文《TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support》,展示了该公司最新的TPU v4超级计算机。谷歌相信TPU v4的性能、可伸缩性和可用性将使其成为支持LaMDA、MUM、PaLM等大规模语言模型的主力产品。

该研究论文的作者称,在类似规模的系统中,TPU v4 比 Nvidia A100 快 1.2-1.7 倍,功耗低 1.3-1.9 倍。
TPU v4 Vs TPU v3
谷歌开发的TPU是专用的硬件加速器,用于构建机器学习模型,特别是深度神经网络。它们针对张量运算进行了优化,可以显著提高大规模ML模型的训练和推理效率。据说在2016年谷歌的人工智能“AlphaGo”与围棋高手李世石9段的比赛中就使用了TPU 。
在2021年I/O 开发者大会上,TPU v4 芯片正式亮相。

△谷歌CEO Sundar Pichai 在I/O 2021 上宣布了 TPU v4
谷歌工程师和论文作者 Norm Jouppi 和 David Patterson 解释说,由于互连技术和特定领域加速器 (DSA) 方面的关键创新,谷歌 TPU v4 有了以下方面的进步:
在扩展 ML 系统性能方面比 TPU v3 有了近 10 倍的飞跃
与当代 ML DSA 相比,提高能源效率约 2-3 倍
在内部部署的数据中心上,通过这些DSA可将二氧化碳排放量减少约20倍
TPU v4 生产工作负载在各种模型类型上的可扩展性如下图所示。

与上一代TPU v3相比,TPU v4 的速度提高了 2.1 倍,性能提高了 2.7 倍。此外,TPU v4 芯片的平均功率通常仅为 200W。
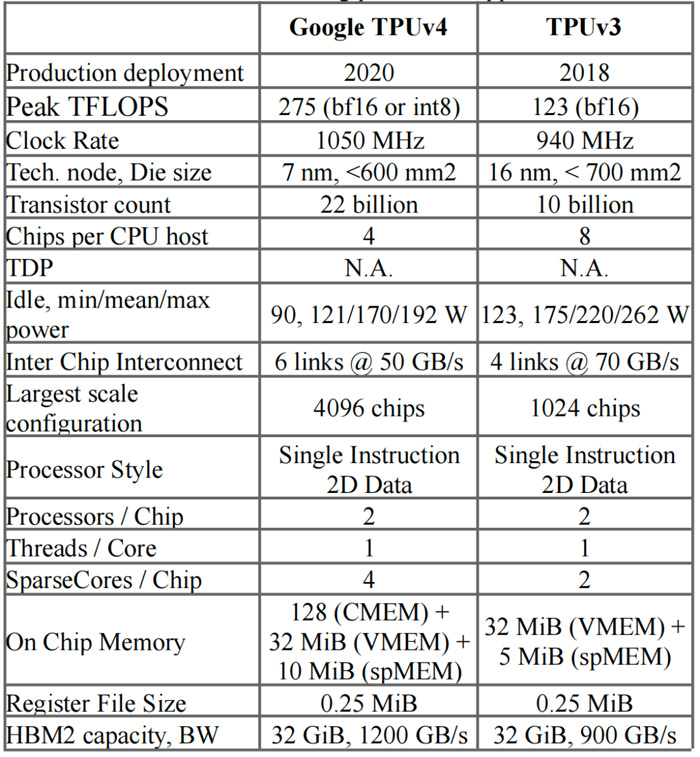
△TPU v4和TPU v3 [Jou20]特性对比
下图是 TPU v3 设备。v3 版本包含 4 个芯片,每个芯片包含 2 个内核和总共 32GB HBM 内存。每个内核包含矢量处理单元 (VPU)、标量单元和两个 128 × 128 矩阵乘法单元(MXU)(TPUv1 为 256 × 256)。
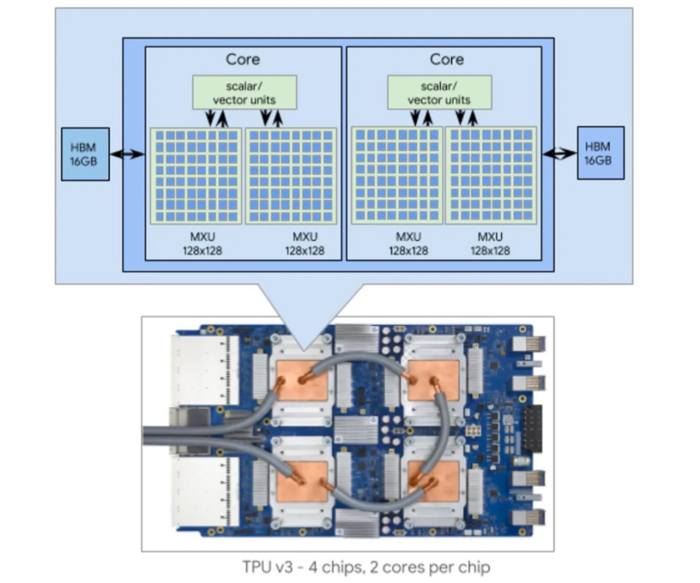
与 TPU v3 一样,TPU v4 包含两个 Tensor Core (TC)。每个 TC 包含四个 128×128 矩阵乘法单元 (MXU)、一个向量处理单元 (VPU) 和一个向量存储器 (VMEM)。

△TPU v4封装和印刷电路板(PCB),带有4个液冷封装
TPU v4 可以快速轻松地更改拓扑以适应应用程序、节点数量和运行作业的系统,从而显着缩短训练时间。每个 TPU v4 还集成了 SparseCores 数据流处理器,可将依赖于嵌入的模型加速 5 至 7 倍,但仅使用 5% 的芯片面积和功率。
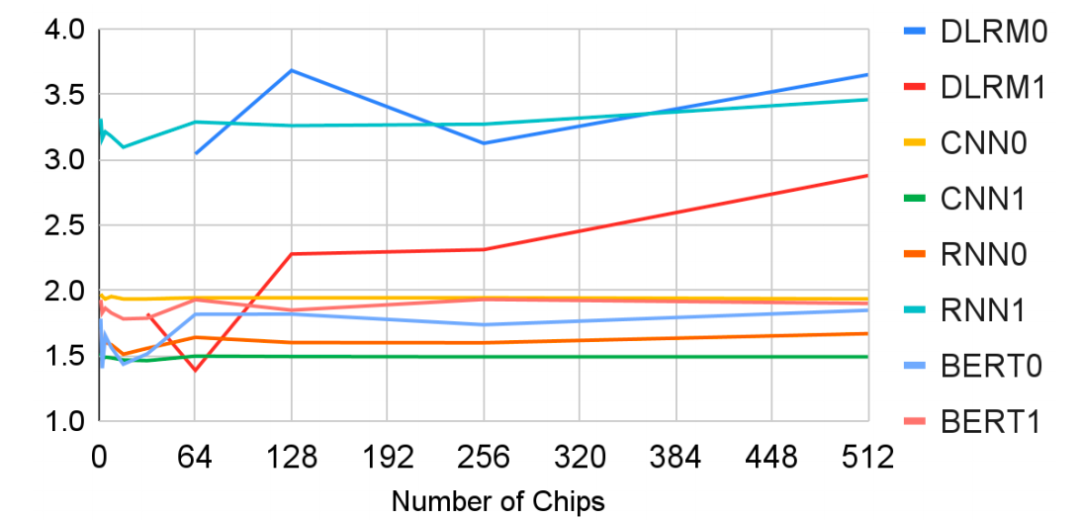
△相同切片大小下TPU v4 和 v3的加速
OCS
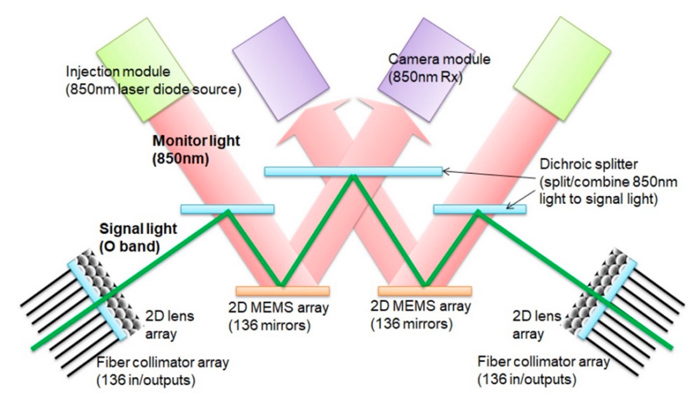
TPU v4版本的一个关键改进是利用了OCS (光电路交换机),TPU v4 是第一台部署可重构 OCS 的超级计算机。OCS 能够动态重新配置其互连拓扑,以提高规模、可用性、利用率、模块化、部署、安全性、功率和性能。与 Infiniband 相比,OCS 的成本更低、功耗更低、速度更快,成本不到系统成本的 5%,功率不到系统功率的 3%。
动态 OCS 可重新配置性也有助于提高可用性。因为它可以通过切换电路轻松绕过故障组件。可用性对于机器学习超级计算机很重要,因为训练大型 AI 模型和产品(例如谷歌的 Bard 和 OpenAI 的 ChatGPT)需要运行大量芯片数周至数月。
下图显示了 OCS 如何使用两个 MEM 阵列工作,不需要光到电到光的转换,也不需要耗电的网络分组交换机,从而节省了电力。
谷歌介绍,TPU v4主要与Pod相连发挥作用,每一个TPU v4 Pod中有4096个TPU v4单芯片,得益于OCS独特的互连技术,能够将数百个独立的处理器转变为一个系统。每一个TPU v4 Pod可以达到1 exaflop级的算力,这相当于1000万台笔记本电脑之和。
对标Nvidia A100
Nvidia 从生成式人工智能热潮中开始获利,市场对 A100 的需求飙升,A100 是用于训练大型语言 AI 模型(如 OpenAI 的 GPT-4)的芯片。目前Nvidia 在人工智能模型训练和部署市场上占据90%的市场份额,谷歌TPU v4能否为其夺得一席之地呢?
谷歌称在类似规模的系统中,TPU v4 比 Graphcore IPU Bow 快 4.3-4.5 倍,比 Nvidia A100 快 1.2-1.7 倍,功耗低 1.3-1.9 倍。但值得注意的是,谷歌并没有将 TPU v4 与Nvidia最新的AI芯片H100进行比较。
H100采用了 4nm 架构,TPU v4 采用的是 7nm 架构。谷歌表示,由于 H100 是在谷歌芯片推出后使用更新技术制造的,所以没有将其第四代产品与Nvidia当前的旗舰 H100 芯片进行比较。

Nvidia 在 ML Perf 测试中名列前茅
在谷歌发布TPU v4消息后,Nvidia也发布了一篇博客文章,其中创始人兼首席执行官黄仁勋指出 A100 于三年前首次亮相,并且Nvidia 芯片 H100 (Hopper) GPU 提供的性能比 A100 高出 4 倍。
此外,MLPerf 3.0近日发布了最新测试结果,Nvidia最新一代Hopper H100计算卡在MLPerf AI测试中创造了新纪录。
Nvidia 指出,它运行了所有 ML Perf 基准测试,包括通过网络将模型数据提供给服务器的最新网络模型,而不是将参数加载到系统中的新网络模型。ML Perf 结果显示,Nvidia的 H100 Tensor Core GPU 在涉及 AI 推理的每项测试中均具有最高性能。该公司表示,得益于一系列新的软件优化,自去年 9 月以来,GPU 的性能提升高达 54%。

△Nvidia H100 SXM per-accelerator MLPerf Inference v2.1和v3.0的比较
Nvidia H100集成了800亿个晶体管,采用台积电N4工艺,是全球范围内最大的加速器,拥有Transformer引擎和高度可扩展的NVLink互连技术(最多可连接达256个H100 GPU,相较于上一代采用HDR Quantum InfiniBand网络,带宽高出9倍,带宽速度为900GB/s)等功能,可推动庞大的AI语言模型、深度推荐系统、基因组学和复杂数字孪生的发展。
黄仁勋表示,三年前当公司推出 A100 时,AI 世界仅由计算机视觉主导,但现在生成式 AI 已经到来。“这正是我们构建 Hopper 的原因,它使用 Transformer Engine 专门针对 GPT 进行了优化。MLPerf 3.0 强调了 Hopper 提供的性能是 A100 的 4 倍。下一阶段的生成人工智能需要新的人工智能基础设施来训练具有高能效的大型语言模式。”
随着人工智能的重要性不断提高,谷歌和Nvidia等公司正在激烈竞争,以开发最高效、最强大的人工智能芯片和系统。虽然谷歌称其TPU v4超级计算机的性能优于Nvidia 的A100,但TPU v4与Nvidia 最新的H100芯片相比如何还有待观察。随着行业的发展,我们可以期待人工智能芯片技术的更多进步,推动更多的创新。
来源:SDNLAB





