
今年3月,英特尔宣布了“IDM 2.0”战略,斥资200亿美元新建新的晶圆厂,重启晶圆代工业务,同时引入代工合作伙伴;随后在7月,英特尔又推出了最新的制程工艺和封装技术,并放出豪言,要在2024年反超台积电;仅仅过了1个月不到,英特尔又来秀肌肉了。

△英特尔CEO基辛格
8月19日,在英特尔“架构日”活动上,英特尔发布了全新的x86内核架构、首个性能混合架构Alder Lake、针对基础设施的IPU、下一代至强可扩展处理器Sapphire Rapids、全新的GPU芯片Alchemist SoC和迄今为止最为复杂的Ponte Vecchio SoC等一系列重磅产品悉数登场。
一、全新的x86内核架构:性能核与能效核来袭
众所周知,在Arm很早就推出了big-LITTLE大小核架构,以实现在一个SoC当中性能和能效之间的平衡。而在2019年的CES上,英特尔也推出了类似大小核架构的全新SoC平台“Lakefield”,只不过Lakefield的大小核架构是基于英特尔“Foveros”3D封装技术来实现的,而且大小是完全不同代际的X86微架构,大核并非专为高性能设计,小核也并未专为高能效而设计。
而在此次的“架构日”活动上,英特尔推出了专门设计的“能效核”微架构和“性能核”微架构。
能效核:Gracemont
全新的英特尔能效核微架构,曾用代号“Gracemont”,旨在面对当今多任务场景,提高吞吐量效率并提供可扩展多线程性能。此高能效x86微架构在有限的硅片空间实现多核任务负载,并具备宽泛的频率范围。该架构致力通过低电压能效核降低整体功率消耗,为更高频率运行提供功率热空间。这也让能效核提升性能,以满足更多动态任务负载。
具体来说,能效核拥有5000个条目的分支目标缓存区,可以实现更准确的分支预测;指令缓存增大至64KB,可以在不耗费内存子系统功率的情况下保存可用指令;集成了英特尔的首款“按需指令长度解码器”,可生成预解码信息加速现代工作负载;英特尔的簇乱序执行解码器,也可在保持能效的同时,每周期解码多达6条指令。
在后端方面,Gracemont还具备5组宽度分配、8组宽度引退、256个乱序窗口入口、17个执行端口,以及4个整数ALU、2个载入AGU、2个存储AGU、2个跳转端口、2个整数存储数据、2个浮点/矢量存储、2个浮点/矢量堆栈、以及第3个矢量ALU。
内存系统方面,Gracemont采用了双载入、双存储单元的配置,二级缓存增大至4MB,以及深度缓冲、高级预取器,支持Intel Resource Director资源重定向技术,可以让软件在不同核心、不同软件线程之间实现精准的控制。

此外,Gracemont还支持英特尔®控制流强制技术和英特尔®虚拟化技术重定向保护等功能。同时,还实现了AVX指令集以及支持整数人工智能操作的新扩展。
英特尔表示,利用以上各种技术进步,Gracemont在不耗费处理器功率的情况下对工作负载进行优先级排序,并通过每周期指令数(IPC)改进功能直接提高性能。
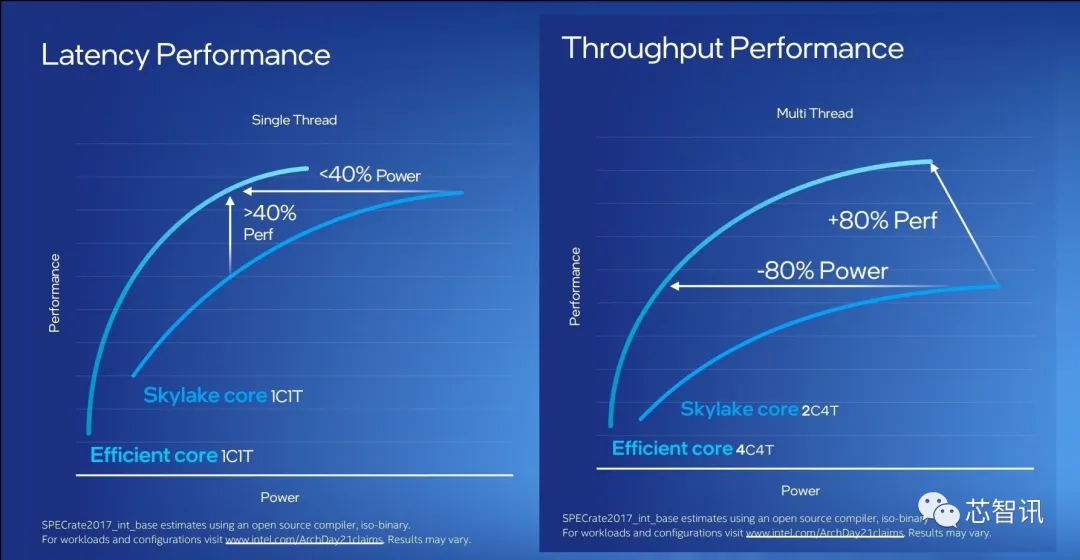
根据英特尔公布的数据显示,相比英特尔最多产的CPU内核Skylake,在单线程性能下,能效核能够在相同功耗下实现40%的性能提升,或在功耗不到40%的情况下提供同等性能。与运行四个线程的两个Skylake内核相比,四个能效核所提供的吞吐量性能,能够在功耗更低的情况下同时带来80%的性能提升,而在提供相同吞吐量性能时,功耗减少80%。
性能核:Golden Cove
英特尔全新性能核微架构,曾用代号 “Golden Cove”, 旨在提高速度,突破低时延和单线程应用程序性能的限制。目前工作负载的代码体积正在不断增长,需要更强的执行能力。数据集也随着数据带宽的需求提升而大幅增加。英特尔全新性能核微架构带来了显著增速同时更好地支持代码体积较大的应用程序。
英特尔表示,Golden Cove性能核拥有更宽、更深、更智能的架构,旨在提高速度、突破低时延和单线程应用程序性能的限制。

具体来说,Golden Cove性能核的解码器由4个增至6个,同时每时钟周期执行由6µop缓存增至8µop,解码长度从16字节翻番至32字节;在乱序引擎部分,分配由5路增至6路,执行端口由10个增至12个,调度器尺寸增大,重排序缓冲区(ROB)从352条目增至512条目,两倍多于AMD Zen3,仅次于苹果M1(大约630条目),重命名和分配阶段也可以执行更多指令。
整数执行引擎部分,增加了第五个整数执行端口,所有五个端口都可以执行ALU、LEA,理论上就原生ALU吞吐能力而言是最宽的x86内核。
矢量执行引擎部分,增加了新的快速加法器(FADD),比传统FMA单元效率更高、延迟更低,FMA单元则增加支持FP16浮点数据类型,属于AVX-512指令集的一部分。
载入和存储部分,通过载入AGU增加了一个专用的执行端口,这样载入端口从2个增至3个,拥有更大的物理寄存器文件(physical register files),拥有512条目的重排序缓冲区,载入缓冲和存储缓冲更深,载入延迟更低,提高了分支预测准确度,降低了有效的一级时延,优化了二级的全写入预测带宽。

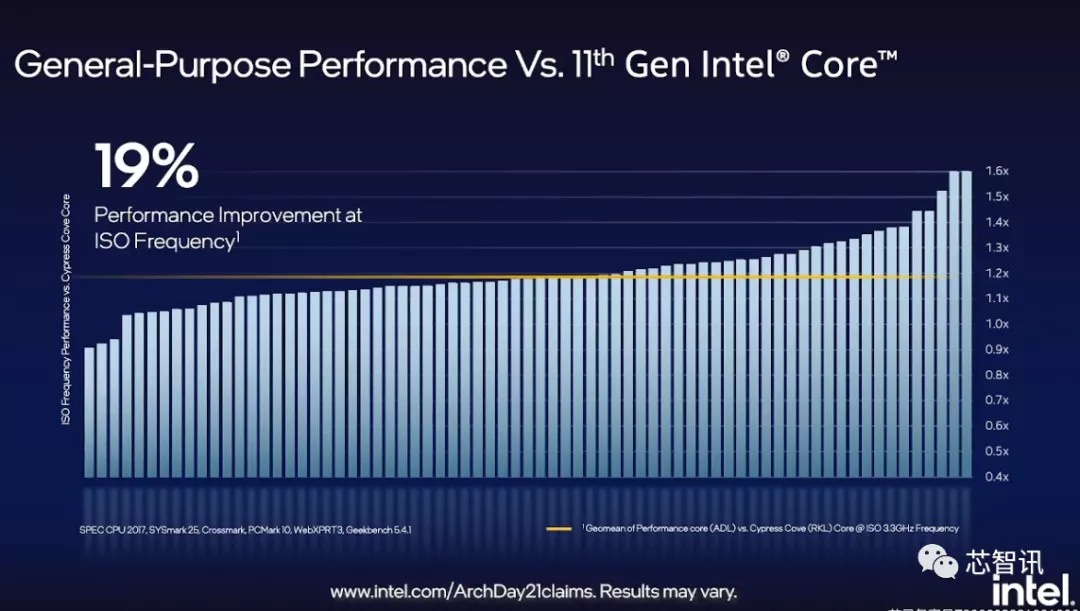
英特尔称,Golden Cove性能核是英特尔有史以来构建的性能最高的CPU内核,突破了低时延和单线程应用程序性能的极限。比如,相比目前的第11代英特尔®酷睿™处理器架构(Cypress Cove),在通用性能的ISO频率下,针对大范围的工作负载实现了平均约19%的改进。
另外,Golden Cove配合英特尔®高级矩形扩展(AMX,包括专用硬件和新指令集架构,以明显提高矩阵乘法运算),内置下一代AI加速提升技术,可以AI工作负载的加速性能带来了指数级提升。
英特尔硬件线程调度器:实现能效与性能核智能化无缝调度
对于SoC来说,即使配备了能效核与性能核,要想很好的发挥出最佳的性能和能效体验,还需要能够进行智能化的无缝的调度,使得能效核与性能核能够更好的协作,各种不同类型的任务负载能够实时的交由最为适合的核心来承担。
为此,“英特尔硬件线程调度器”也就应运而生,它将直接被内置于硬件中,可以更精细地监控指令组合、每个内核当前状态以及相关的微架构遥测,从而帮助操作系统做出更智能的调度决策,让操作系统能够在恰当的时间将合适的线程放置在合适的内核上。
英特尔表示,其硬件线程调度器具有动态性和自适应性——它会根据实时的计算需求调整调度决策——而非一种简单的、基于规则的静态方法。
据介绍,英特尔已经通过与微软合作,进一步优化英特尔硬件线程调度器在Windows11上的性能表现。
根据英特尔公布的数据显示,英特尔硬件线程调度器可以在最短30微秒的时间里确定一个线程的性质、归属,而传统的系统调度器需要上百甚至几百微秒,还可能分配错误。此外,英特尔硬件线程调度器还会针对性地优化频率,尤其是在移动端,保证效率的同时还能提高能效,而且可以在微秒级别调整频率。
首款性能混合架构:Alder Lake
作为英特尔首款集成了性能核和能效核的客户端架构,第12代酷睿Alder Lake带来了显著的性能和能效的提升,其基于Intel 7制程工艺打造,并支持最新内存和最快I/O,比如DDR5和PCIe 5.0。

这里需要强调的是,Alder Lake并不是一款芯片,而是面向客户端的一系列芯片的基础架构。因此,Alder Lake内核搭配是可以进行选择的,最高支持8个性能核和8个能效核,共计24个线程,三级缓存最高可达30MB。
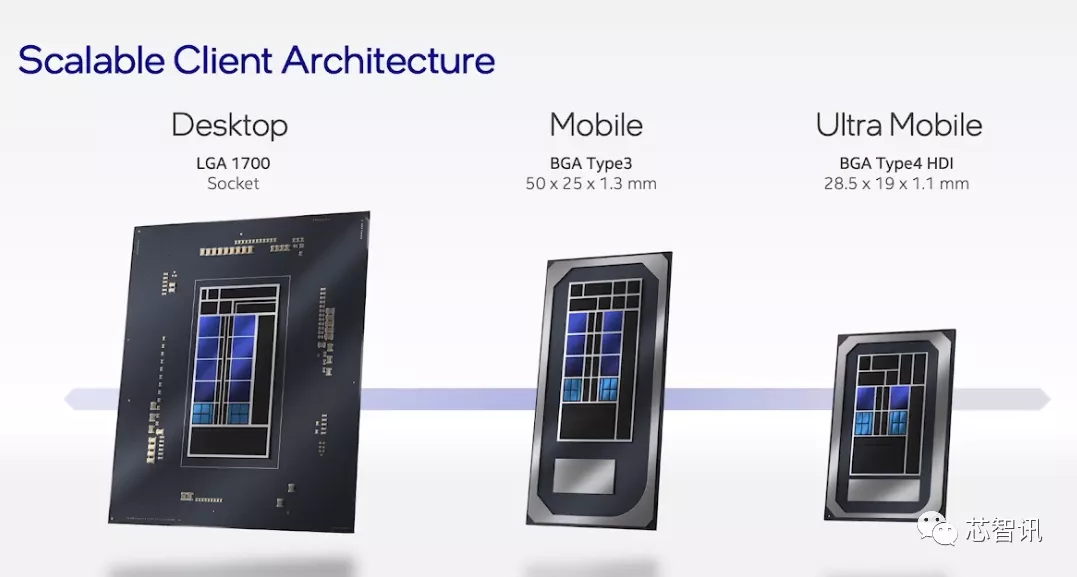
此次,英特尔公布了针对桌面平台、移动平台和超级移动类型产品设计的三类Alder Lake架构芯片。
其中,面向桌面平台的S系列,采用的是LGA1700独立封装,最多8个性能核心和8效能核心,24线程,集成32EU核显,功耗最高125W;面向移动产品的低功耗版的UP3系列,采用BGA Type3整合封装,最多6个性能核心和8个效能核心,20线程,集成最多96EU核显,功耗12W~35W;面向超级移动平台产品的超低功耗的UP4系列,采用BGA Type4整合封装,最多2个性能核心和8个效能核心,集成最多96EU核显,功耗低至9W。
以上3大系列芯片都将集成新一代GNA 3.0高斯神经加速器,它们的差异主要在于核心规模,以及对一些原生功能的支持。比如,只有移动版才标配IPU(图像处理器单元)、雷电4和Wi-Fi6,而且UP3提供4个雷电4端口,UP4则仅支持2个。
英特尔表示,其首款性能混合架构Alder Lake是高度可扩展的SoC架构,将提供惊人的性能,支持从超便携式笔记本,到发烧级,到商用台式机的所有客户端设备。
而为了应对如此高度可扩展架构的挑战,还需要在不影响功率的情况下满足计算和I/O代理对带宽超乎寻常的需求。为了解决这一挑战,英特尔设计了三种独立的内部总线,将各个模块串联了起来,每一种都采用基于需求的实时启发式后处理方式。
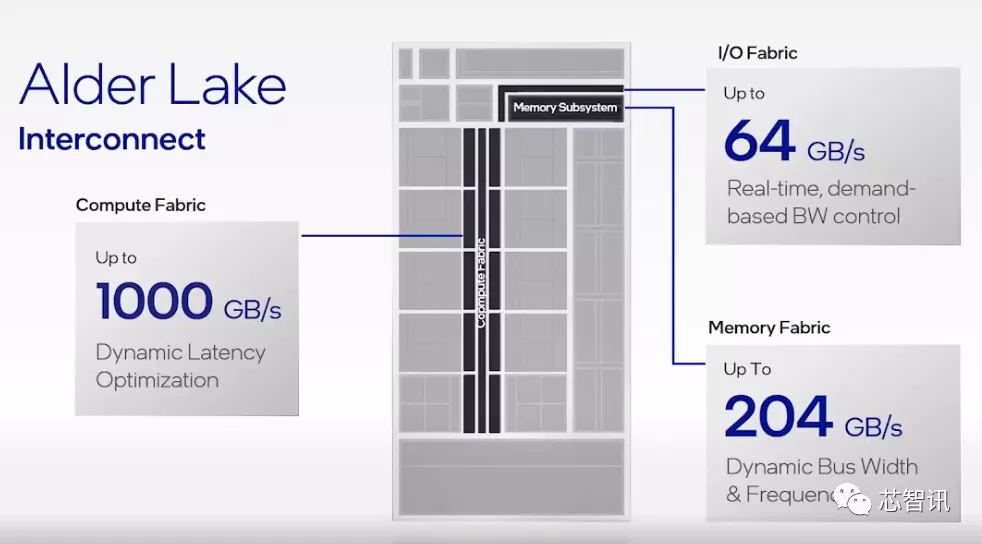
第一个是Compute Fabric,用于连接CPU和高速缓存,带宽可达1TB/s,支持动态缓存优化。第二个是Memory Fabric,用于连接内存和其他模块,带宽最高204GB/s,支持动态位宽和频率。第三个是I/O Fabric,用于输入输出,最高带宽64GB/s,支持基于需求的实时带宽控制。
二、台积电6nm工艺,首款Xe HPG微架构的锐炫游戏显卡来了
早在2018年6月,英特尔就曾在分析师大会上证实,将进军独立显示芯片(Discrete GPU)市场,挑战 Nvidia 与AMD。在2020年的CES上,英特尔首次向公众展示了基于Xe架构的独立显卡“Xe DG1”,并展示了“Xe DG1”在笔记本电脑上运行FPS大作《命运2》的试玩影像。
如果说Xe DG1是英特尔针对中低端独立显卡市场的一款试水产品,那么基于Xe HPG微架构的“锐炫”Alchemist显卡(原来的DG2)则是面向高端市场的一款重磅产品,将直接对NVIDIA和AMD发起挑战。
8月16日晚间,英特尔公布了针对消费市场的全新高性能显卡产品品牌——英特尔锐炫™(Intel®Arc™),基于Xe HPG微架构所打造,专为游戏和创作工作负载提供发烧级的高性能。相应的产品包括:首款基于Xe HPG微架构的Alchemist显卡(原来的DG2),还包括代号分别为Battlemage、Celestial和Druid的后续几代产品。
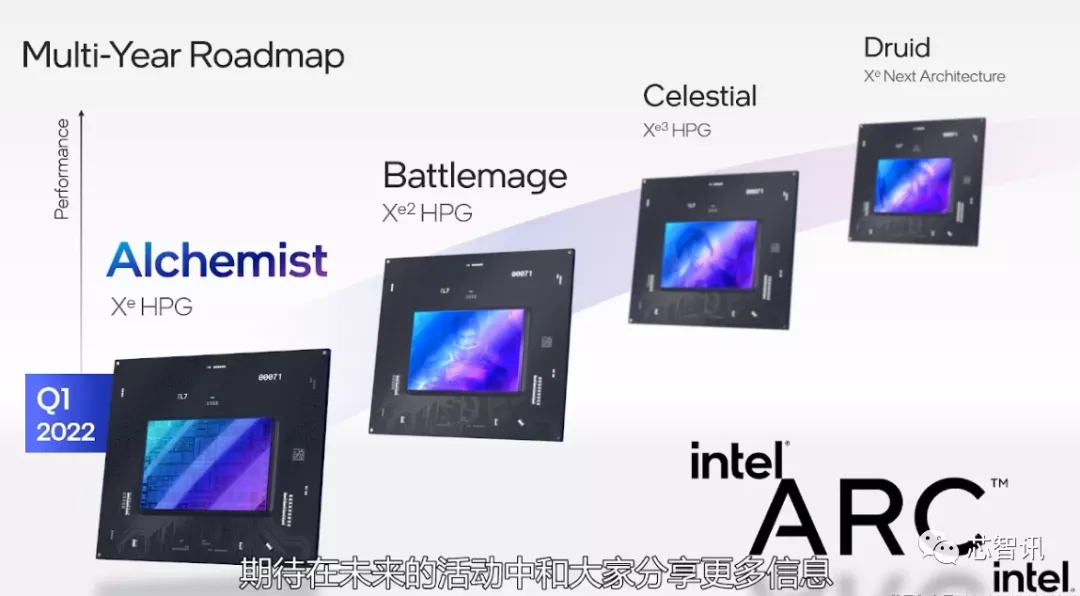
在今天的“架构日”活动上,英特尔详细介绍了Xe HPG微架构和Alchemist显卡的细节。
全新Xe HPG微架构
Xe HPG微架构是融合了英特尔Xe LP、HP和HPC 微架构的优势,采用全新的Xe内核,是一款聚焦计算、可编程且可扩展的元件。
不同于英特尔以往GPU以及此前的DG1所采用的EU(执行单元)核心,Alchemist的Xe HPG微架构则采用了全新的Xe-Core,包含矢量和矩阵(张量)ALU单元、零级和一级缓存、载入存储单元等等。
具体来说,Xe-Core内有16个矢量单元,或者叫矢量引擎,每个每时钟周期可处理256位,又可细分为8个FP32 ALU单元,因此每个Xe核心每时钟周期颗处理器128个FP32操作。同时Xe-Core还有16个矩阵数学单元,或者叫矩阵引擎(XMX),处理矩阵、张量操作,每个每时钟周期可处理1024位,可以是64个FP16操作,也可以是128个INT8操作。
Xe-Core的上一层级则是“渲染切片”(Render Slice),专为DX12 Ultimate设计,每个包含4个Xe核心、4个支持DirectX Raytracing(DXR)和Vulkan Ray Tracing的新光线追踪单元、4个纹理采样器、几何前端、光栅前端、2个像素后端。
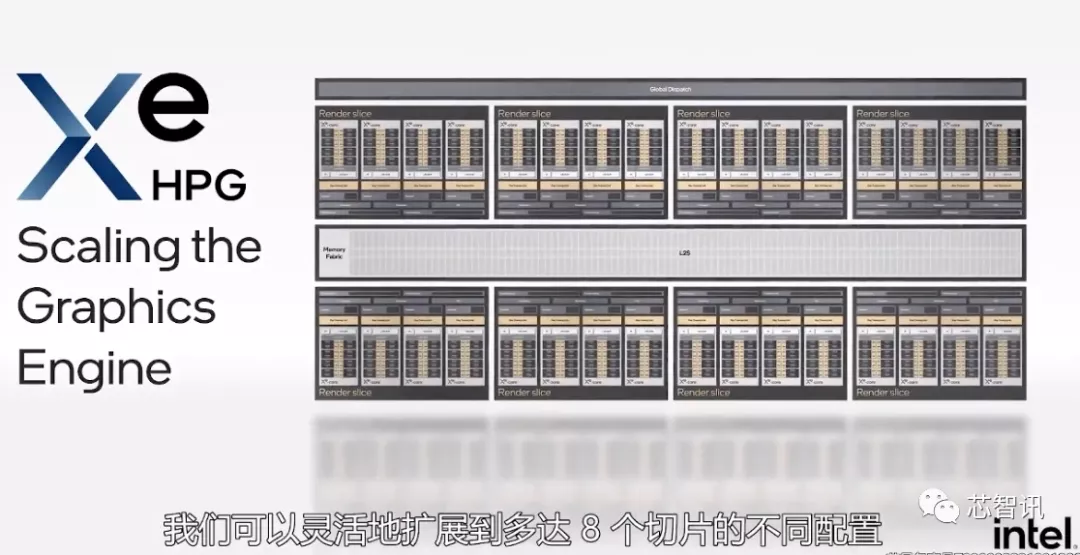
此次发布的Alchemist GPU将拥有渲染切片的配置,拥有高速缓存和共享内部显存。
台积电6nm代工
特别值得一提的是,Alchemist GPU是交由台积电6nm工艺代工的。去年就有传闻称,英特尔的Xe GPU将交由台积电代工。在今年3月,英特尔CEO基辛格公布了IDM 2.0战略,其中重要的一部分就是,将会不断扩大与第三方代工厂的合作,并且会涵盖以先进制程技术生产一系列模块化芯片。甚至从2023年开始,英特尔的客户端和数据中心部门生产核心计算产品也将会部分交由第三方代工厂生产。
英特尔之所以将Alchemist GPU交由台积电代工,更多的应该是从产品竞争力上来考虑的,毕竟台积电在独立显卡GPU代工上拥有着丰富的经验,在先进制程的代工成本上也相对更具优势,NVIDIA和AMD的独立显卡GPU也是交由台积电代工的。
台积电业务发展高级副总裁Kevin Zhang博士也表示,“台积电很高兴Intel选择台积电N6技术作为他们的Alchemist独立显卡GPU解决方案。借助N6,台积电在性能、密度和功率效率方面实现了最佳平衡,是现代GPU的理想选择。我们对与英特尔在Alchemlst系列独立显卡GPU上的合作感到高兴”。
软件优先
对于显卡来说,硬件指标固然重要,但是要想充分发挥出硬件的性能,软件也同样重要。
英特尔也表示,其显卡设计的核心是软件优先。目前其正与开发人员密切合作进行Xe微架构的设计,力求与行业标准保持一致。并且通过在一个统一的代码库中涵盖集成和独立显卡产品的驱动设计,英特尔的第一款高性能游戏显卡将性能和质量放在首位。
此外,英特尔还完成了内核显卡驱动程序组件的重新架构,特别是内存管理器和编译器。从而使计算密集型游戏的吞吐量提高了15% (至多80%),游戏加载时间缩短了25%。
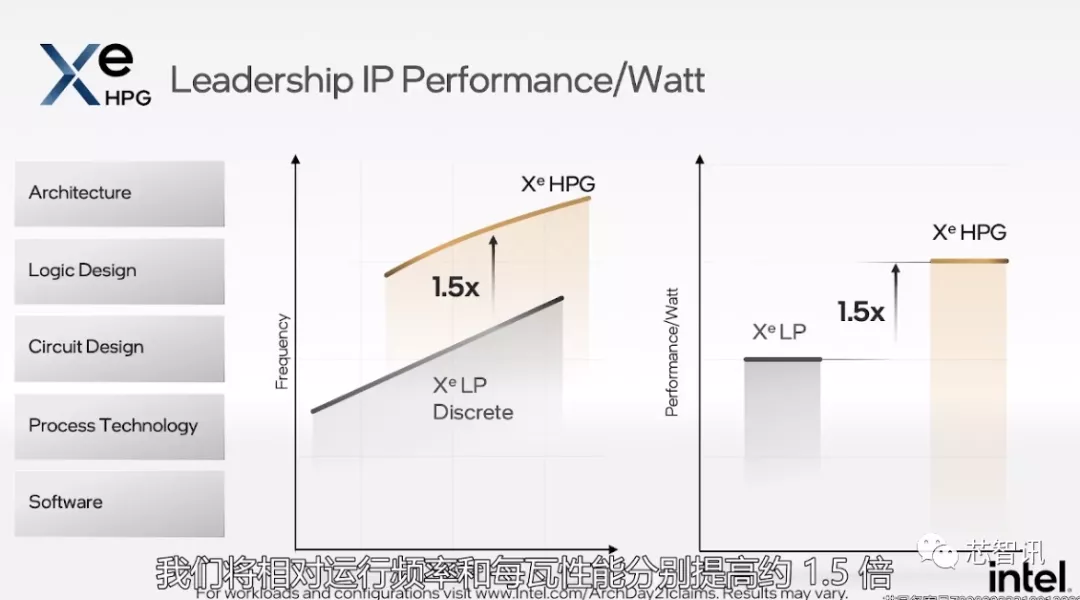
频率及效能相比Xe LP微架构提升1.5倍
英特尔表示,通过架构、逻辑设计、电路设计、制程工艺技术、软件的全方位优化,相比于Xe LP微架构,Xe HPG微架构可以实现1.5倍的频率提升、1.5倍的能效提升。
之前基于Xe LP微架构的DG1的基础频率1GHz,加速频率1.5GHz,照此推算,Alchemist显卡的频率应该在2GHz左右。网上有推测数据称,Alchemist显卡FP32算力大约16.4TFlops,性能几乎是DG1的8倍。

△英特尔公司高级副总裁兼加速计算系统和图形事业部总经理Raja Koduri展示Alchemist SoC晶圆。
英特尔称,Alchemist系列显卡将于2022年第一季度上市,其将采用基于硬件的光线追踪和人工智能驱动的超级采样,为DirectX 12 Ultimate提供全面支持。
全新升频技术XeSS
为配合Alchemist显卡应用,英特尔还利用Alchemist的内置XMX AI加速,带来了一种可实现高性能和高保真视觉的全新升频技术。
XeSS的工作原理是通过从相邻像素,以及对前一帧进行运动补偿,来重建子像素细节。而如果重构借由经过训练的神经网络以及Alchemist的内置XMX AI加速执行,则可提供高性能和高画质,同时性能提升高达两倍。另外,XeSS凭借DP4a指令,在包括集成显卡在内的各种硬件上也能提供基于AI的超级采样。
英特尔还通过现场演示,展示了那些只能在低画质设置或低分辨率下玩的游戏也能凭借XeSS在更高画质设置和分辨率下顺利运行。

据介绍,多家早期的游戏开发商已开始使用XeSS, 本月将向独立软件供应商(ISV)提供XMX初始版本的SDK,DP4a版本将于今年晚些时候推出。
三、Ponte Vecchio:迄今为止最复杂的SoC,拥有超1000亿颗晶体管
除了首款基于Xe HPG微架构的Alchemist独立显卡之外,英特尔此次还带来了基于Xe HPC微架构的Ponte Vecchio,这是迄今为止最复杂的SoC,拥有47个单元(Tiles),且各个单元可能基于不同晶圆制造厂(英特尔或台积电)的不同工艺,通过英特尔的Foveros 3D技术封装在一起,总共拥有超过1000亿颗晶体管,提供业界领先的每秒浮点运算次数(FLOPs)和计算密度,以加速AI、HPC和高级分析工作负载。

不同于Alchemist的针对图形渲染的Xe HPG微架构,Xe HPC主要是针对数据中心的各种高性能计算需求,因此Xe HPC内部的Xe-Core也主要针对计算进行了优化,所以其内部结构与Xe HPG不同,包括8个512-bit矢量引擎、8个4096-bit矩阵引擎,数量对比Xe HPG少了一半,但位宽则在原有基础上分别增加了1倍和3倍,算力大幅提升。同时,还配套了一个宽加载/存储单元,每个时钟周期取回512字节数据。另外,每个Xe核心还集成了512KB一级数据缓存,这是目前业内最大的,而且可以通过软件配置作为暂存区使用,即可共享内部显存。
同样,Ponte Vecchio的Xe-Core之上的“切片”也比Alchemist的“切片层”要大很多,其每个切片集成多达16个Xe-Core(达到了Alchemist的4倍),同时还有8MB一级缓存、16个光追单元、一个硬件上下文(Hardware Context)单元,其中光追支持光线遍历、边界框相交、三角形相交,提供固定函数计算。
4个“切片”可以组成一个堆栈,即一个GPU,所以其内部总共有64个Xe-Cores、64个光追单元、4个硬件上下文。同时,堆栈内还有大规模二级缓存、4个HBM2e内存控制器、1个媒体引擎、8个Xe链路,以及拷贝引擎、PCle控制器。

通过英特尔的EMIB封装和堆栈间互连技术,Xe HPC可以轻松的支持双堆栈设计,Xe-Core核心数直接翻倍到128个。
每个Xe HPC GPU双堆栈之间还可以通过Xe链路进行互连,支持最多8颗并行,算力直接暴力乘以8倍,性能暴涨!

了解完Xe HPC的强大之后,英特尔推出的包含47个运算单元的Ponte Vecchio无疑也是相当的强大。
据介绍,Ponte Vecchio每个负责计算单元拥有8个Xe-Core、4MB的一级缓存,基于台积电5nm工艺,可通过Foveros 3D技术进行3D堆叠,凸点间距仅36μm。
Ponte Vecchio的每个基础单元主要是起到连接作用,包括了PCIe 5.0总线、HBM2e内存、MDFI链路、EMIB桥接等一系列复杂的I/O和高带宽组件。基于Intel 7制程工艺打造,面积为640mm²,集成了高达144MB二级缓存。

Xe链路单元是由台积电7nm工艺制造,主要负责不同GPU之间的连接,是面向HPC、AI的纵向扩展的关键,每个单元有8条链路,实现了最高90G Serdes。
目前Ponte Vecchio处于A0版本阶段,已走下生产线进行上电验证,并成功运行了数百个工作负载,实测FP32吞吐性能超过45TFlops,Memory Fabric缓存带宽超过5TB/s,互连带宽超过2TB/s。

△英特尔公司高级副总裁兼加速计算系统和图形事业部总经理Raja Koduri展示Ponte Vecchio
Ponte Vecchio将有多种产品形态,最基本的单芯片做成OAM模块,集成到一个载体基板上。此外,还可以利用Xe Links实现四模块并联,组成一个大的系统,甚至可以进行四个系统互联,与2S的下一代英特尔至强可扩展处理器“Sapphire Rapids”进行组合,提供更为强大的性能。

据英特尔透露,目前Ponte Vecchio已开始向客户提供限量样品,并已成功被添加到“极光”(Aurora)百亿亿次级超级计算机的扩展解决方案中。预计,Ponte Vecchio预计将于2022年面向HPC和AI市场发布。
四、下一代英特尔至强可扩展处理器“Sapphire Rapids”
一直以来,英特尔在先进封装技术领域都是出于业界领先地位,先进封装技术也是英特尔关键的六大技术支柱之一。此次,英特尔在架构日上发布的下一代英特尔至强可扩展处理器“Sapphire Rapids”就首次将自家的嵌入式多芯片互连桥接(EMIB)封装技术引入到了至强可扩展处理器当中。


Sapphire Rapids的核心是一个分区块、模块化的SoC架构,采用EMIB封装技术,将四个芯片模块整合在一起,在保持单芯片CPU接口优势的同时,具有显著的可扩展性。
Sapphire Rapids基于Intel 7制程工艺技术,采用英特尔全新的性能核微架构。此前的资料显示,其内部的四个芯片模块当中,每一个芯片模块内部最多拥有14核心(外加一个可能隐藏的),借助于EMIB封装技术,组成总计56核心。
Sapphire Rapids支持DDR5和PCIe 5.0总线,同时封装集成HBM2e高带宽内存,四个芯片模块每个最大容量16GB,合计最多64GB,带宽高达1TB/s。DDR5内存、HBM2e内存可以并行使用,支持缓存、混合多种模式。Sapphire Rapids还提供了一个单一、平衡的统一内存访问架构,借助CXL 1.1等技术,每个线程均可完全访问缓存、内存和I/O等所有单元上的全部资源,由此实现整个SoC具有一致的低时延和高横向带宽。
Sapphire Rapids还配备了新的内置加速器引擎包括:
英特尔®加速器接口架构指令集(AIA)——支持对加速器和设备的有效调度、同步和信号传递。
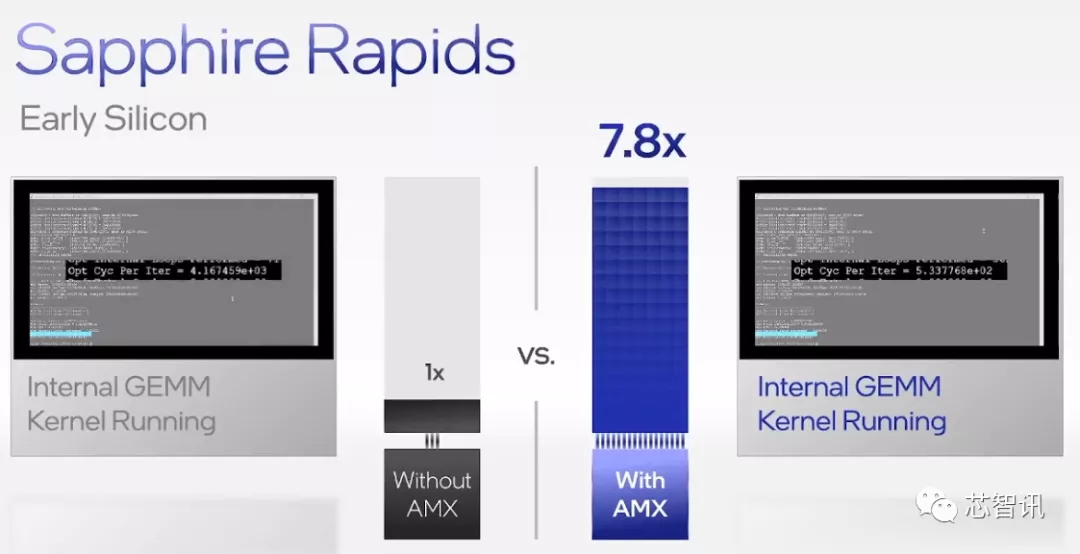
英特尔®高级矩阵扩展(AMX),可为深度学习算法核心的Tensor处理提供大幅加速。其可以在每个周期内进行2000次 INT8运算和1000次 BFP16运算,实现计算能力的大幅提升。

使用早期的Sapphire Rapids芯片,与使用英特尔AVX-512 VNNI指令的相同微基准测试版本相比,使用新的英特尔AMX指令集扩展优化的内部矩阵乘法微基准测试的运行速度提高了7倍以上,为AI工作负载中的训练和推理上提供了显着的性能提升。
英特尔®数据流加速器(DSA)——旨在卸载最常见的数据移动任务,这些任务会导致数据中心规模部署中的开销。英特尔DSA改进了对这些开销任务的处理,以提供更高的整体工作负载性能,并可以在CPU、内存和缓存以及所有附加的内存、存储和网络设备之间移动数据。
英特尔表示,Sapphire Rapids代表了业界在数据中心平台上的一大进步。该处理器可在不断变化且要求日益增高的数据中心使用中提供可观的计算性能,并对工作负载进行优化,以在云、微服务和AI等弹性计算模型上提供高性能。
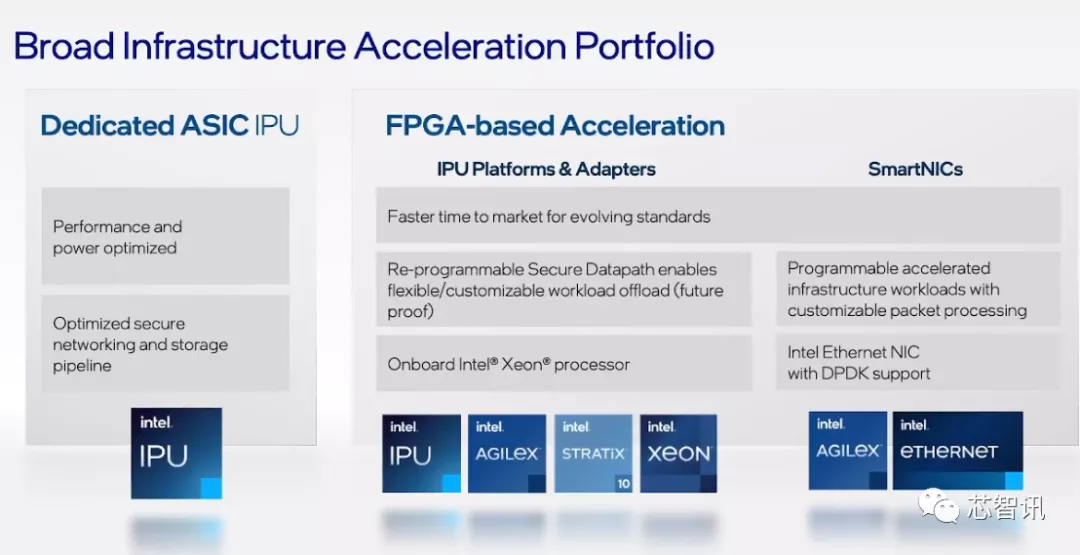
五、基础设施处理器(IPU)
早在今年6月,英特尔就正式发布了其面向基础设施应用的 IPU 处理器,以满足数据中心和云服务提供商的最新需求。
根据英特尔的定义,IPU(Infrastructure Processing Unit)是一种可编程网络设备,旨在使云和通信服务提供商减少在中央处理器 (CPU) 方面的开销,并充分释放性能价值。利用 IPU,客户能够部署安全稳定且可编程的解决方案,从而更好地利用资源,平衡数据处理与存储的工作负载。
目前Nvidia、Marvell、Broadcom等芯片厂商都有针对基础设施应用推出智能网卡(SmartNIC)或网络数据处理单元 (DPU),其也是一种新型的可编程处理器,主要也是帮助云服务商减少在CPU方面的开销,与英特尔的IPU比较类似。
但是,英特尔表示,DPU最核心的任务是I/O数据的预处理和后处理,进行加速。而IPU则主要是管理存储流量, 云运营商可以将基础设施任务卸载到IPU上,以减少时延,同时通过无磁盘服务器架构有效利用存储容量。借助IPU,客户可以通过一个安全、可编程、稳定的解决方案更好地利用资源,使其能够平衡处理与存储。
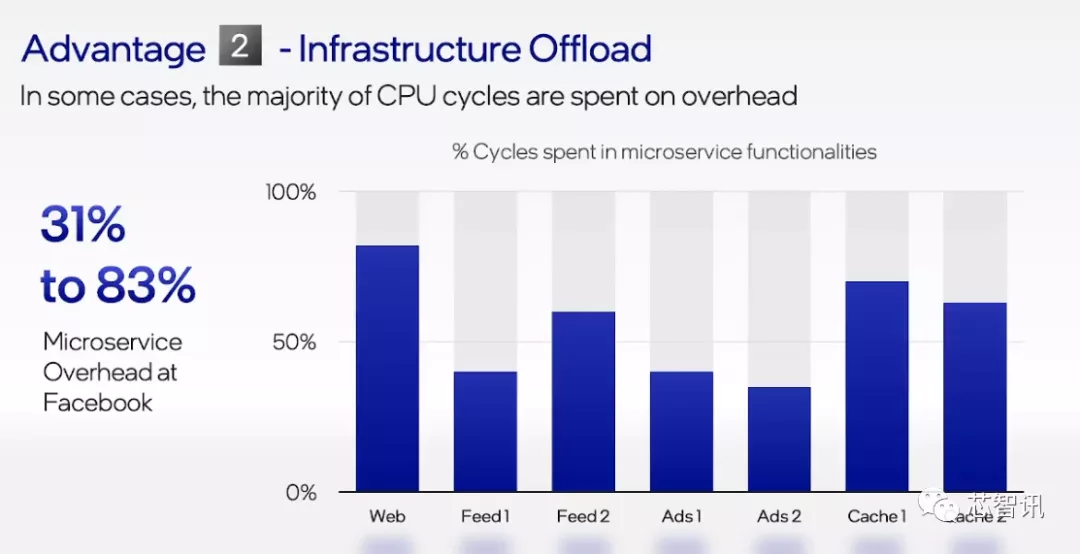
英特尔在今年6月就曾表示,通过至强D、FPGA和以太网组件的广泛部署,英特尔已在IPU市场出货量上位于领先地位。英特尔首个基于 FPGA 的 IPU 平台已为多个云服务提供商完成部署,此外英特尔的首款 ASIC IPU 也正在测试中。
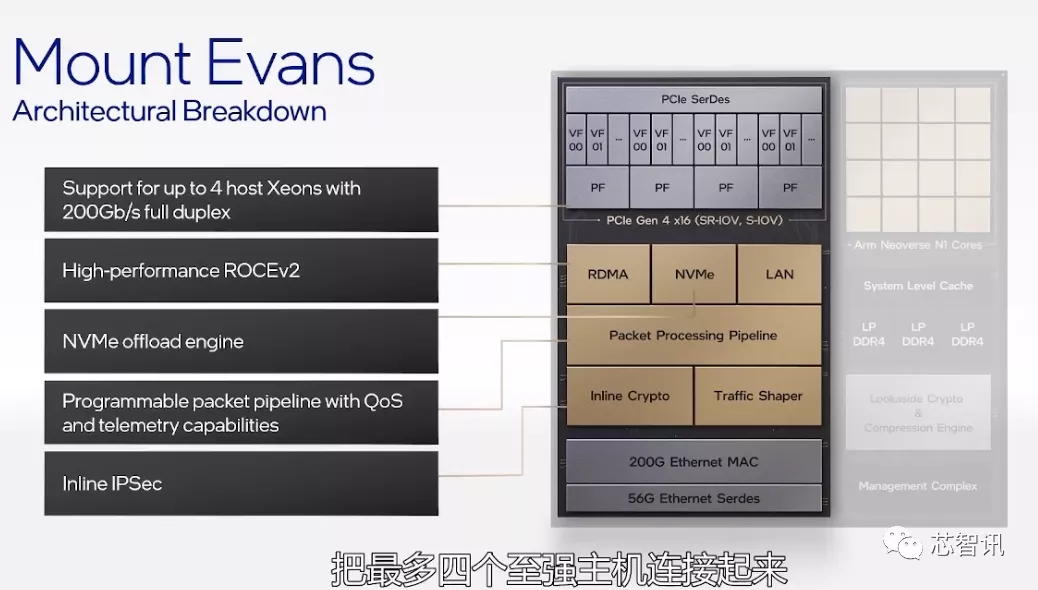
Mount Evans:英特尔首个ASIC IPU,首次采用Arm CPU内核
在此次的架构日活动上,英特尔正式推出了旗下首个ASIC IPU——Mount Evans,以及全新的基于FPGA的IPU参考平台Oak Springs Canyon和英特尔N6000加速开发平台。
据介绍,Mount Evans是英特尔与一家一流云服务提供商共同设计和开发的,它融合了多代FPGA SmartNIC的经验。
特别需要指出的是,英特尔Mount Evans的CPU核心采用了Arm针对基础设施推出的Neoverse N1内核,这也使得Mount Evans成为了英特尔推出的首款基于Arm CPU内核的芯片。
英特尔之所以选则Arm CPU内核,应该是出于性能、功耗、芯片面积及成本方面的考虑。目前众多的厂商推出的DPU也都是基于Arm CPU架构。
此外,Mount Evans能通过 PCIe连接最多4个至强主机,同时还有针对NVMe的存储接口以模拟NVMe设备,还支持英特尔高性能Quick Assist技术,部署高级加密和压缩加速。支持ROCEv2的硬件加密加速功能,能同时针对资料管理与安全进行加速处理。
IPU参考平台:Oak Springs Canyon
Oak Springs Canyon是一个基于英特尔至强D处理器和英特尔Agilex FPGA构建的IPU参考平台。
可支持卸载Open Virtual Switch(OVS)等网络虚拟化功能以及NVMe over Fabric和 RoCE v2等存储功能,并提供硬化的加密模块,提供更安全、高速的2x 100Gb以太网网络接口。
Oak Springs Canyon这是一款可扩展、开源软件和硬件基础设施,可以使得英特尔的合作伙伴和客户能够使用英特尔开放式FPGA开发堆栈(英特尔OFS)定制其解决方案。
Oak Springs Canyon支持使用现有普遍部署的软件环境进行编程,包括已在x86上优化的DPDK和SPDK。
英特尔N6000加速开发平台
英特尔N6000加速开发平台,代号为“Arrow Creek”,是专为搭载至强服务器设计的SmartNIC。
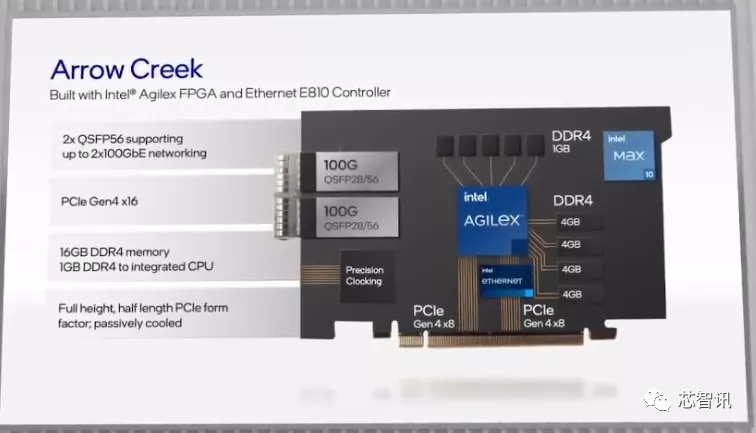
其特性包括:在功耗、效率和性能方面处于行业领先地位的英特尔Agilex FPGA。用于高性能的100GB网络加速的英特尔以太网800系列控制器;支持多种基础设施工作负载,使通信服务提供商(CoSP)能够提供灵活的加速工作负载,如Juniper Contrail、OVS和SRv6,它以英特尔PAC-N3000的成功为基础,该产品已在部分业界一流的CoSP中部署。
六、oneAPI工具包:超过20万次单独安装
英特尔目前拥有着自己的CPU、GPU、FPGA、IPU、人工智能处理器等众多XPU产品,有时客户还会选择不同厂商的不同芯片进行搭配,现在英特尔还加入了基于Arm CPU的产品。而不同类型、不同厂商的芯片的开发,可能有着专有的编程语言和编程模型,这也给众多需要进行跨平台开发编程的开发者带来了很大的挑战。
为此,英特尔在去年推出了oneAPI项目,提供了一个开放、规范、跨架构和跨厂商的统一软件栈,让开发者能够摆脱专有语言和编程模型的束缚。
oneAPI 支持直接编程和 API 编程,并将提供统一的语言和库,可以在包括 CPU、GPU、FPGA 和 AI 加速器等不同硬件上,提供完整的本地代码性能。
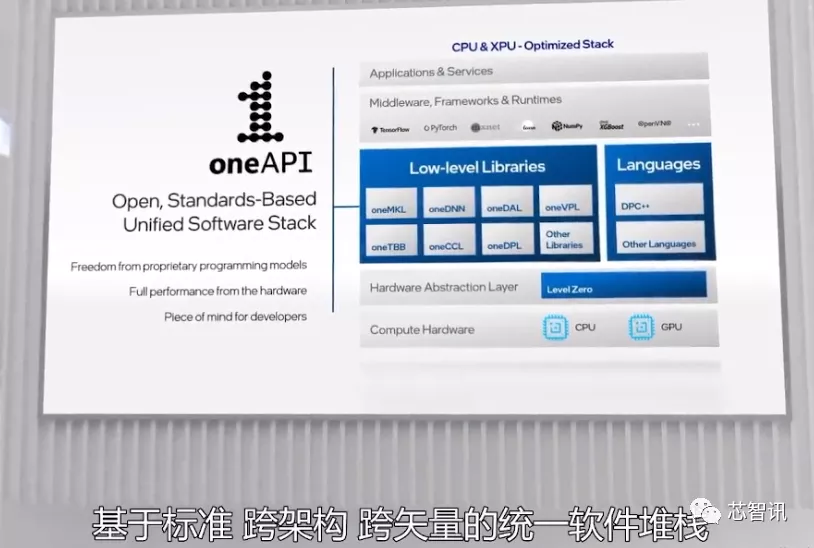
目前,NVIDIA GPU、AMD GPU和Arm CPU均有Data Parallel C++(DPC++)和oneAPI库。oneAPI正在被独立软件提供商、操作系统供应商、终端用户和学术界广泛采用。行业领导者正在协助发展该规范,以支持更多的用例和架构。
同时,英特尔还提供了商业产品,包括基本的oneAPI基础工具包,它在规范语言和库之外增加了编译器、分析器、调试器和移植工具。
据英特尔介绍,目前英特尔的oneAPI工具包已拥有超过20万次单独安装;市场上部署的300多个应用程序采用了oneAPI的统一编程模型;超过80个HPC和AI应用程序使用英特尔oneAPI工具包在Xe HPC微架构上运行。

接下来,英特尔将在5月发布的1.1版临时规范,为深度学习工作负载和高级光线追踪库添加了新的图形接口,预计将在年底完成。
小结:
正如开篇所提到的,在基辛格接任英特尔CEO之后,将英特尔的重心全面转向了半导体设计和制造,在宣布IDM 2.0战略之后,就开始大刀阔斧的按照既定的战略快速推进。
在3月宣布重启晶圆代工业务之后,7月在公布制程工艺和封装技术进展的同时,就宣布已经与高通达成了Intel 20A工艺节点上的合作,同时在先进封装上也与亚马逊AWS达成了合作。
并且英特尔一直被外界诟病为“挤牙膏”的制程工艺进展也开始大幅加速,自今年开始量产Intel 7 制程,此后每一年将会推出新一代的全新制程,这相比之前英特尔本就已经多次延宕的“Tick-Tock”节奏成倍提升。而根据英特尔路的计划,将在2025年量产20A(20埃米,相当于台积电2nm)制程。
在3月宣布扩大与第三方代工厂的合作之后,现在基于台积电6nm工艺的首款Xe HPG微架构Alchemist独立显卡也正式发布了,此外Ponte Vecchio SoC的内部的部分单元也有采用台积电5nm工艺代工。
同时,英特尔在独立显卡设计上持续发力和制造上所采用的灵活的策略,也为英特尔接下来与NVIDIA、AMD在独立显卡市场的竞争带来了更多的机会。
此外,面对业界早已流行的“大小核”混合架构发展的趋势,英特尔此次也推出了全新的X86性能核与能效核微架构,奠定了未来数年英特尔CPU发展路径。面对目前SoC朝着异构集成、Chiplet等方向发展的趋势,英特尔此次推出的拥有47个运算单元、多种制程工艺和先进封装技术、高达1000亿颗晶体管Ponte Vecchio SoC也很好的向外界秀了秀“肌肉”。
可以说,如今的英特尔更加的自信和开放。自信的是,对于自身的产品设计能力、先进制程技术、先进封装技术以及产品力的自信。开放则更是双向的,既对外开放自身的核心的先进制程和先进封装技术能力,同时也愿意引入台积电等第三方的晶圆代工厂商,乃至Arm的CPU内核。
编辑:芯智讯-浪客剑






